



Suivre le rythme d’une industrie qui évolue aussi rapidement que l’IA est une tâche difficile. Donc, en attendant qu'une IA puisse le faire, voici ce résumé des sujets récents dans le monde de l'apprentissage automatique, ainsi que des recherches et des expériences notables.
Deepmind
Le laboratoire de recherche et développement en IA appartenant à Google, Deepmind, a lancé un document dans lequel il propose un cadre pour évaluer les risques sociaux et éthiques des systèmes d’IA.
Le moment choisi pour sa publication, qui nécessite différents niveaux d’implication de la part des développeurs d’IA, des développeurs d’applications et des « parties prenantes du grand public » dans l’évaluation et l’audit de l’IA, n’est pas un hasard.
Bientôt le Sommet sur la sécurité de l'IA, un événement parrainé par le gouvernement britannique qui rassemblera des gouvernements internationaux, des sociétés d'IA de premier plan, des groupes de la société civile et des experts en recherche pour se concentrer sur la meilleure façon de gérer les risques liés aux dernières avancées en matière d'IA. y compris l’IA générative (par exemple ChatGPT, diffusion stable, etc.). Le Royaume-Uni est planification introduire un groupe consultatif mondial sur l’IA, sur le modèle du Groupe d’experts intergouvernemental sur l’évolution du climat des Nations Unies, composé d’un groupe tournant d’universitaires qui rédigeront régulièrement des rapports sur les développements de pointe en matière d’IA et les dangers qui y sont associés.
DeepMind exprime très visiblement son point de vue, avant les discussions politiques sur le terrain lors de ce sommet de deux jours. Et, pour rendre à César ce qui mérite à César, le laboratoire de recherche soulève des points raisonnables (bien qu'évidents), tels que l'appel à des approches pour examiner les systèmes d'IA au « point d'interaction humaine » et les manières dont ces systèmes pourraient être utilisés et leur impact. sur la société.
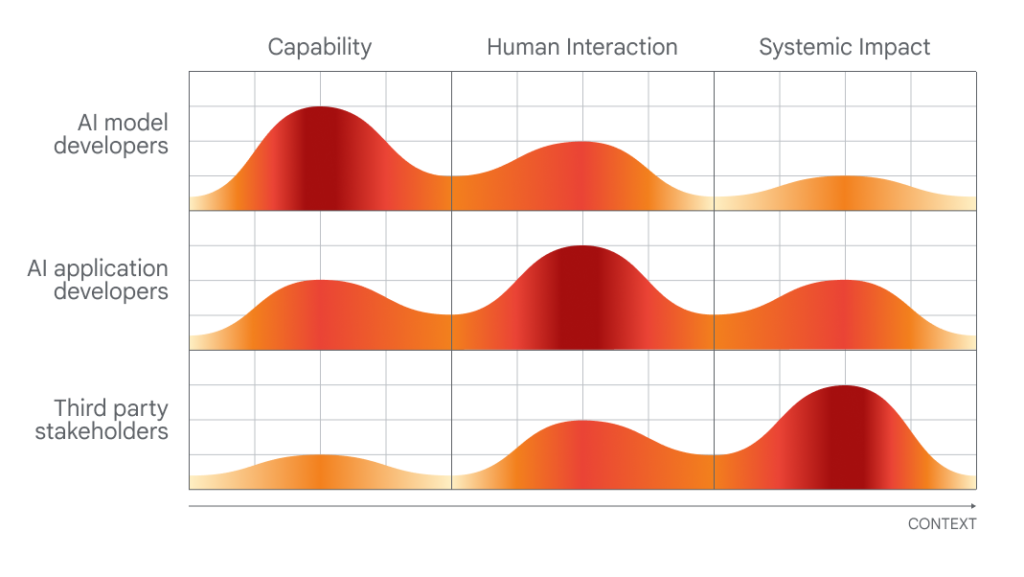
Graphique montrant quelles personnes seraient les plus aptes à évaluer quels aspects de l'IA.
Mais lorsque l'on évalue les propositions de DeepMind, il est instructif de consulter le score de la société mère du laboratoire, Google, dans une étude publié par des chercheurs de Stanford qui classe les dix meilleurs modèles d'IA en fonction de leur degré d'ouverture.
Évalué sur 100 critères, y compris si son fabricant a divulgué les sources de ses données de formation, des informations sur le matériel utilisé, le travail impliqué dans la formation et d'autres détails, PaLM 2, l'un des modèles phares d'IA d'analyse de texte de Google, obtient un pauvres 40,%.
Or, DeepMind n’a pas développé PaLM 2, du moins pas directement. Mais le laboratoire n'a toujours pas été transparent sur ses propres modèles, et le fait que sa société mère ne respecte pas les mesures de transparence clés suggère qu'il n'y a pas beaucoup de pression descendante pour que DeepMind fasse mieux.
D’un autre côté, en plus de ses réflexions publiques sur les politiques, DeepMind semble prendre des mesures pour changer la perception selon laquelle il reste silencieux sur les architectures et le fonctionnement interne de leurs modèles. Le laboratoire, aux côtés d’OpenAI et d’Anthropic, s’est engagé il y a plusieurs mois à fournir au gouvernement britannique un « accès anticipé ou prioritaire » à ses modèles d’IA pour soutenir l’évaluation et la recherche sur la sécurité.
La question est : est-ce simplement informatif ? Après tout, personne n’accuserait DeepMind de philanthropie : le laboratoire génère des centaines de millions de dollars de revenus chaque année, principalement en accordant des licences internes à ses travaux aux équipes de Google.
Peut-être que le prochain grand test éthique du laboratoire sera Gemini, son prochain chatbot IA, dont le PDG de DeepMind, Demis Hassabis, a promis à plusieurs reprises qu'il rivaliserait avec le ChatGPT d'OpenAI dans ses capacités. Si DeepMind veut être pris au sérieux sur le plan éthique de l'IA, il devra détailler de manière complète et approfondie les faiblesses et les limites de Gemini, et pas seulement ses forces. Nous surveillerons certainement de près l’évolution des choses dans les mois à venir.
Autres nouvelles
Voici quelques autres histoires notables sur l’IA :
- Une étude Microsoft révèle des failles dans GPT-4 : Un nouvel article scientifique associé à Microsoft a analysé la « fiabilité » (et la toxicité) des grands modèles de langage (LLM), notamment le GPT-4 d'OpenAI. Les co-auteurs ont découvert qu’il était plus facile de demander des réponses à une ancienne version de GPT-4 qu’à d’autres LLM qui produisaient des textes toxiques et biaisés.
- ChatGPT effectue des recherches sur le Web et DALL-E 3: à propos d'OpenAI, la société a officiellement lancé sa fonctionnalité de navigation Internet pour ChatGPT, certains trois semaines après la réintroduction de la fonctionnalité en version bêta après plusieurs mois d'interruption. Dans le même ordre d’idées, OpenAI est également passé de DALL-E3 en version bêta, un mois après l'introduction de la dernière incarnation du générateur de texte en image.
- Challengeurs GPT-4V : OpenAI devrait bientôt publier GPT-4V, une variante de GPT-4 qui comprend à la fois les images et le texte. Mais deux alternatives open source l’emportent : LLaVA-1.5 et Fuyu-8B, un modèle de startup bien financée Expert. Ni l’un ni l’autre n’est aussi performant que le GPT-4V, mais les deux s’en rapprochent et, plus important encore, sont gratuits à utiliser.
- L'IA peut-elle jouer à Pokémon ?: Ces dernières années, un ingénieur logiciel basé à Seattle Peter Whidden a entraîné un algorithme d'apprentissage par renforcement pour naviguer dans le premier jeu classique de la série Pokémon. Actuellement, il n’atteint que Cerulean City, mais Whidden est convaincu qu’il continuera à s’améliorer.
- Tuteur de langue alimenté par l'IA : Google cible Duolingo avec une nouvelle fonctionnalité de recherche Google conçue pour aider les gens à pratiquer (et à améliorer) leurs compétences en anglais. La nouvelle fonctionnalité, déployée dans les prochains jours sur les appareils Android dans certains pays, offrira une pratique orale interactive aux apprenants en langues traduisant vers ou depuis l'anglais.
- Amazon lance davantage de robots d'entrepôt : lors d'un événement, Amazon annoncé qui commencera à tester le robot bipède Agility dans ses installations, Chiffre. Cependant, en lisant entre les lignes, rien ne garantit qu'Amazon commencera réellement à mettre en œuvre Digit dans ses entrepôts, qui utilisent actuellement plus de 750.000 XNUMX systèmes robotiques.
- Simulateurs sur simulateurs : La même semaine où Nvidia a démontré comment appliquer un LLM pour aider à écrire du code d'apprentissage par renforcement afin de guider un robot naïf alimenté par l'IA pour mieux effectuer une tâche, Meta a publié Habitat 3.0. La dernière version de l'ensemble de métadonnées pour la formation d'agents IA dans des environnements intérieurs réalistes. Habitat 3.0 ajoute la possibilité pour des avatars humains de partager l'espace en réalité virtuelle.
- Les titans chinois de la technologie investissent dans leur rival OpenAI : Zhipu AI, une startup basée en Chine développant des modèles d'IA pour rivaliser avec ceux d'OpenAI et d'autres dans le domaine de l'IA générative, annoncé qui a levé jusqu'à présent 2.500 milliards de yuans (340 millions de dollars) de financement total cette année. Cette annonce intervient alors que les tensions géopolitiques entre les États-Unis et la Chine s’accentuent et ne montrent aucun signe d’apaisement.
- Les États-Unis étouffe l’approvisionnement en puces d’IA de la Chine : Au sujet des tensions géopolitiques, l'administration Biden a annoncé cette semaine une série de mesures visant à freiner les ambitions militaires de Pékin, notamment de nouvelles restrictions sur les expéditions de puces. intelligence artificielle de Nvidia à la Chine. A800 et H800, les deux puces IA que Nvidia a spécialement conçues pour continuer à expédier en Chine et qui seront concernés par ces nouvelles règles.
- Les replays de chansons pop d'IA deviennent viraux : apparaît recouvrant une curieuse tendance : comptes tiktok qui utilisent l'IA pour faire chanter des personnages comme Homer Simpson des chansons rock des années 90 et 2000 comme "Sent comme de l'alcool d'ados». Ils sont amusants en surface, mais il y a une nuance sombre dans l’ensemble de la pratique.
Plus d'apprentissage automatique
Les modèles d’apprentissage automatique conduisent systématiquement à des progrès dans les sciences de la vie. AlphaFold et RoseTTAFold sont des exemples de la manière dont un problème persistant (le repliement des protéines) pourrait en fait être banalisé avec le bon modèle d'IA. Aujourd'hui, David Baker (créateur de ce dernier modèle) et ses collègues de laboratoire ont élargi le processus de prédiction pour inclure plus que la simple structure des chaînes d'acides aminés pertinentes. Après tout, les protéines existent dans une soupe d’autres molécules et atomes, et il est essentiel de prédire comment elles interagiront avec les composés ou les éléments perdus dans l’organisme pour comprendre leur forme et leur activité réelles. RoseTTAFold All-Atom C’est un grand pas en avant pour la simulation des systèmes biologiques.
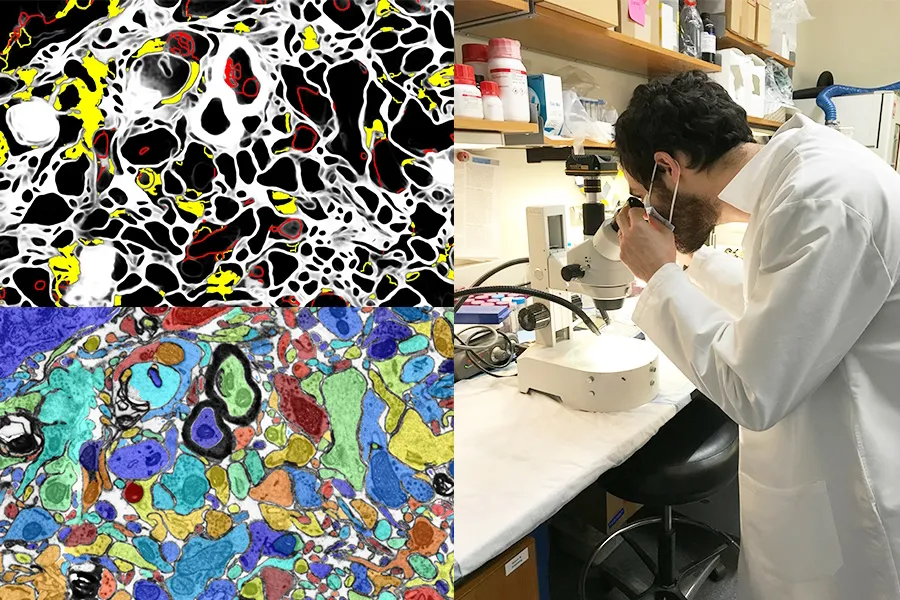
MIT/Université Harvard
Disposer d’une IA visuelle qui améliore le travail en laboratoire ou agit comme un outil d’apprentissage est également une excellente opportunité. Le projet SmartEM du MIT et Harvard place un système de vision par ordinateur et un système de contrôle ML à l’intérieur d’un microscope électronique à balayage, qui conduisent ensemble l’appareil à examiner intelligemment un échantillon. Vous pouvez éviter les zones de faible importance, vous concentrer sur les zones intéressantes ou claires et également étiqueter intelligemment l'image résultante.
L’utilisation de l’IA et d’autres outils de haute technologie à des fins archéologiques ne se démode jamais (pour ainsi dire). Qu'il s'agisse d'un lidar (un capteur qui émet des impulsions lumineuses de manière ininterrompue et capte leurs retours) révélant des villes et des routes mayas ou comblant les lacunes de textes grecs anciens incomplets, c'est toujours intéressant à voir. Et cette reconstitution d'un rouleau qui aurait été détruit lors de l'éruption volcanique qui a dévasté Pompéi est l'une des plus impressionnantes à ce jour.

Tomodensitométrie interprétée par ML d'un papyrus roulé et brûlé. Le mot visible dit « Violet ».
Luke Farritor, étudiant en informatique à l'Université du Nebraska-Lincoln, a formé un modèle d'apprentissage automatique pour amplifier des motifs subtils dans les numérisations du papyrus roulé et carbonisé, invisibles à l'œil nu. Leur méthode était l'une des nombreuses méthodes tentées dans le cadre d'un défi international visant à lire les manuscrits et pouvait être affinée pour un travail universitaire précieux. Les informations sont publié par Nature.. Qu'y avait-il sur le parchemin ? Jusqu’à présent, seul le mot « violet », mais même cela fait perdre la tête aux papyrologues.
Une autre victoire académique pour l’IA est en ce système pour examiner et suggérer des citations sur Wikipédia. Bien sûr, l'IA ne sait pas ce qui est vrai ou factuel, mais elle peut déterminer à partir du contexte à quoi ressemblent un article et une citation Wikipédia de haute qualité et rechercher des alternatives sur le site et sur le Web. Personne ne suggère de laisser les robots gérer la célèbre encyclopédie en ligne pilotée par les utilisateurs, mais cela pourrait contribuer à renforcer les articles pour lesquels les citations manquent ou dont les éditeurs sont incertains.

Exemple de problème mathématique résolu par Llemma.
Les modèles linguistiques peuvent être affinés sur de nombreux sujets et, étonnamment, les mathématiques avancées en font partie. Llemma est un nouveau modèle ouvert préparé pour des tests mathématiques et des articles pouvant résoudre des problèmes assez complexes. Ce n'est pas la première : Minerva de Google Research travaille sur des capacités similaires, mais son succès sur des ensembles de problèmes similaires et son efficacité améliorée montrent que les modèles "ouverts" (quel que soit ce terme) sont compétitifs dans ce domaine. Il n’est pas souhaitable que certains types d’IA soient dominés par des modèles propriétaires, c’est pourquoi la réplication ouverte de leurs capacités est précieuse même si elle n’innove pas.
Il est inquiétant que Meta progresse dans son propre travail académique vers la lecture des pensées, mais comme pour la plupart des études dans ce domaine, la façon dont cela est présenté surestime le processus. Dans un article intitulé « Décodage cérébral : vers une reconstruction en temps réel de la perception visuelle » Il peut sembler qu’ils lisent dans les pensées.

Images montrées aux personnes (à gauche) et l’IA générative devine ce que la personne perçoit (à droite).
Mais c'est un peu plus indirect que ça. En étudiant à quoi ressemble un scanner cérébral à haute fréquence lorsque les gens regardent des images de certaines choses, comme des chevaux ou des avions, les chercheurs peuvent reconstruire en temps quasi réel ce qu'ils pensent que la personne pense ou regarde. Il semble néanmoins probable que l’IA générative ait un rôle à jouer ici, dans la manière dont elle peut créer une expression visuelle de quelque chose, même si cela ne correspond pas directement aux scans.
¿Nous devrions Utiliser l’IA pour lire dans les pensées des gens, si c’est possible ? Demandons à DeepMind (voir ci-dessus).
Enfin, un projet en LAION ce qui est pour le moment plus ambitieux que concret, mais tout aussi louable. L'apprentissage contrastif multilingue pour l'acquisition de représentations audio, ou CLARA, vise à donner aux modèles linguistiques une meilleure compréhension des nuances de la parole humaine. Savons-nous comment un sarcasme ou un mensonge peut être détecté à partir d'indices subverbaux tels que le ton ou la prononciation ? Les machines sont plutôt mauvaises dans ce domaine, ce qui est une mauvaise nouvelle pour toute interaction homme-IA. CLARA utilise une bibliothèque audio et textuelle multilingue pour identifier certains états émotionnels et autres indices non verbaux de « compréhension de la parole ».

{kind=link}