



De la détection des fraudes à la surveillance des cultures agricoles, une nouvelle vague d’entreprises technologiques a émergé, toutes convaincues que leur utilisation de l’IA permettra de relever les défis présentés par le monde moderne.
Cependant, à mesure que le paysage de l’IA mûrit, une préoccupation croissante apparaît : au cœur de nombreuses entreprises d’IA, leurs modèles, deviennent rapidement des marchandises. L’absence notable de différenciation substantielle entre ces modèles commence à soulever des questions quant à la durabilité de leur avantage concurrentiel.
Au lieu de cela, alors que les modèles d’IA restent des éléments fondamentaux de ces entreprises, un changement de paradigme est en train de se produire. La véritable proposition de valeur des entreprises d’IA ne réside désormais plus seulement dans les modèles, mais aussi et surtout dans les ensembles de données qui les sous-tendent. C'est la qualité, l'étendue et la profondeur de ces ensembles de données qui permettent aux modèles de surpasser leurs concurrents.
Sin embargo, en la prisa por llegar al mercado, muchas empresas impulsadas por la IA, incluidas aquellas que se aventuran en el prometedor campo de la biotecnología, se lanzan sin la implementación estratégica de una pila de tecnología especialmente diseñada que genere los datos indispensables necesarios pour apprentissage automatique solide. Cet oubli a des implications substantielles sur la longévité de vos initiatives d’IA.
Comme tu le sais bien spécialiste du capital risque (VC), il ne suffit pas d’examiner l’attrait superficiel d’un modèle d’IA. Au lieu de cela, une évaluation complète de la technologie de l'entreprise est nécessaire pour évaluer son adéquation à son objectif. L’absence d’une infrastructure méticuleusement conçue pour l’acquisition et le traitement des données pourrait signaler la chute d’une entreprise par ailleurs prometteuse.
Cet article propose des cadres pratiques issus de l'expérience acquise dans des startups basées sur l'apprentissage automatique. Ils ne sont pas exhaustifs, mais ils peuvent constituer une ressource supplémentaire pour ceux qui ont la tâche difficile d'évaluer les processus de données des entreprises et la qualité des données qui en résultent et, en fin de compte, de déterminer s'ils sont prêts à réussir.
Des ensembles de données incohérents aux entrées bruyantes, qu’est-ce qui pourrait mal se passer ?
Avant de passer aux cadres, évaluons d'abord les facteurs de base qui entrent en jeu lors de l'évaluation de la qualité des données. Et surtout, que pourrait-il en ressortir mauvais si les données Ils ne sont pas à la hauteur.
Pertinence
Considérons d’abord la pertinence des ensembles de données. Les données doivent s’aligner de manière complexe sur le problème qu’un modèle d’IA tente de résoudre. Par exemple, un modèle d’IA développé pour prédire les prix de l’immobilier nécessite des données couvrant les indicateurs économiques, les taux d’intérêt, les revenus réels et les changements démographiques.
De même, dans le contexte de la découverte de médicaments, il est crucial que les données expérimentales montrent la plus grande prévisibilité possible des effets chez les patients, ce qui nécessite une réflexion experte sur les tests, lignées cellulaires, organismes modèles et autres pertinents.
exactitud
Deuxièmement, les données doivent être exactes. Même une petite quantité de données inexactes peut avoir un impact significatif sur les performances d'un modèle d'IA. Ceci est particulièrement critique dans les diagnostics médicaux, où une petite erreur dans les données pourrait conduire à un diagnostic erroné et potentiellement affecter des vies.
Couverture
Troisièmement, la couverture des données est également essentielle. S’il manque des informations importantes aux données, le modèle d’IA ne pourra pas apprendre aussi efficacement. Par exemple, si un modèle d’IA est utilisé pour traduire une langue particulière, il est important que les données incluent une variété de dialectes différents.
Pour les modèles linguistiques, il s’agit d’un ensemble de données linguistiques « à faibles ressources » ou « à ressources élevées ». Cela nécessite également une compréhension complète des facteurs de confusion affectant le résultat, ce qui nécessite généralement la collecte de métadonnées.
Biais et préjugés
Enfin, le biais des données mérite également un examen rigoureux. Les données doivent être capturées de manière impartiale pour éviter les biais humains ou les biais de modèle. Par exemple, les données de reconnaissance d’images devraient minimiser les stéréotypes. Dans la découverte de médicaments, les ensembles de données doivent couvrir à la fois les molécules efficaces et celles qui échouent afin d’éviter des résultats biaisés. Dans les deux cas, les données seraient considérées comme biaisées et perdraient probablement leur capacité à faire de nouvelles prédictions.
L’impact de données médiocres ne doit pas être sous-estimé. Au mieux, elles aboutissent à un modèle sous-performant, et au pire, elles le rendent totalement inefficace. Cela peut entraîner des pertes financières, des opportunités manquées et même des dommages physiques.
De même, si les données sont biaisées, les modèles produiront des résultats biaisés, ce qui peut encourager la discrimination et les pratiques déloyales. Cela a été particulièrement préoccupant dans le cas des grands modèles linguistiques, qui ont récemment fait l’objet d’un examen minutieux parce qu’ils perpétuent des stéréotypes.
La qualité des données compromise peut également nuire à l’efficacité de la prise de décision, ce qui peut finalement entraîner de mauvaises performances commerciales.
Cadre 1 : Pyramide technologique pour la génération de données
Pour éviter d’investir dans des startups d’IA inefficaces, il est nécessaire d’abord d’évaluer les processus derrière les données. Imaginer le fondement technologique d'une entreprise sous la forme d'une pyramide est un bon point de départ, dans lequel les niveaux fondamentaux ont tendance à avoir le plus grand impact sur les résultats prédictifs. Sans cette base solide, même les meilleurs modèles d’analyse de données et d’apprentissage automatique sont confrontés à des limites importantes.
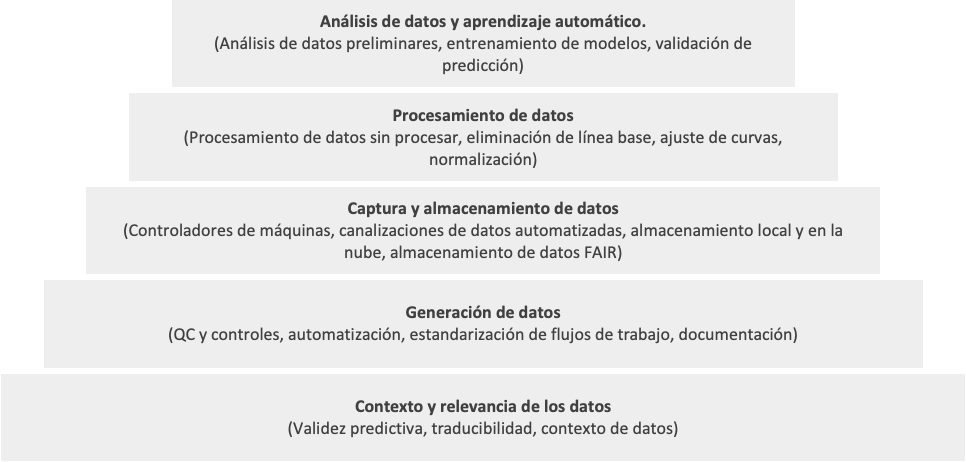
Voici quelques questions de base qu'un VC pourrait initialement poser pour déterminer si le processus de génération de données d'une startup peut réellement créer des résultats utilisables pour l'IA :
- La capture des données est-elle automatisée pour permettre la mise à l'échelle ?
- Les données sont-elles stockées dans des environnements cloud sécurisés avec des sauvegardes automatisées ?
- Comment l’accès aux ressources et infrastructures informatiques pertinentes est-il géré et assuré ?
- Les processus de traitement des données sont-ils entièrement automatisés, avec des contrôles rigoureux de la qualité des données en place pour limiter la contamination par des points de données contaminés ?
- Les données sont-elles facilement accessibles dans toute l’entreprise pour alimenter les modèles d’apprentissage automatique et les décisions basées sur les données ?
- Comment la gouvernance des données est-elle mise en œuvre ?
- Existe-t-il une stratégie de gestion des données ?
- Les versions des données et des modèles ML sont-elles suivies et accessibles, garantissant que les modèles ML fonctionnent toujours avec la dernière version des données ?
Recevoir des réponses solides à ces questions peut aider à déterminer la compréhension qu'a une entreprise des principes sous-jacents de ses pipelines de données. Cette compréhension, à son tour, aidera à mesurer la qualité des résultats du modèle.
Cadre 2 : Les cinq V de la qualité des données
Une fois que les fondements technologiques d’une entreprise sont jugés adaptés à l’IA, elle doit également examiner attentivement la qualité des données résultantes utilisées pour entraîner ses modèles. Un cadre commun utilisé pour capturer la classification de la qualité des données est celui des cinq V de la qualité des données. Ils représentent cinq dimensions clés de la qualité des données que les investisseurs en capital-risque devraient prendre en compte lors de l'évaluation des startups d'IA :
- Véracité : Les données doivent être exactes et véridiques.
- Variété : les données doivent être diverses et représentatives du monde réel.
- Volume : les données doivent être suffisamment volumineuses pour entraîner efficacement le modèle d'IA.
- Rapidité : les données doivent être mises à jour fréquemment pour refléter les changements dans le monde.
- Valeur : Les données doivent être utiles pour que le modèle d'IA puisse en tirer des leçons.
Voici quelques questions d'introduction pour vous aider à évaluer les données d'une entreprise pour les cinq V :
- La startup a-t-elle une bonne hypothèse sur les données qu'elle doit créer pour construire une capacité différenciée ou un modèle utile ?
- Quelles données collectent-ils ?
- Collectent-ils également des métadonnées pertinentes ?
- Comment garantissez-vous l’exactitude et la cohérence des données que vous collectez ?
- Comment la startup envisage-t-elle de gérer les biais liés aux données ?
- Collectez-vous plusieurs exemples pour la même question ou expérience ?
- Dans quelle mesure ces données sont-elles utiles au produit que vous créez ?
- Quelle est la raison de la collecte de ces données ?
- Avez-vous la preuve que vos prédictions s’améliorent grâce à la collecte et à l’utilisation de ces données ? Si oui, comment la quantité de données est-elle corrélée à l’amélioration des prévisions ?
- Est-il facile pour un concurrent de collecter les mêmes données ?
- Combien de temps cela leur prendrait-il et combien cela leur coûterait-il ?
- Spécifiquement pour une société de biotechnologie, dans quelle mesure l'indicateur qu'elle prédit est-il en corrélation avec un critère d'évaluation cliniquement pertinent ? Y a-t-il des preuves de cela ?
- Quel est le projet de la startup pour assurer la qualité de ses données dans le temps ?
- Comment la startup compte-t-elle protéger ses données contre les accès non autorisés ?
- Comment la startup compte-t-elle se conformer aux réglementations en matière de confidentialité des données ?
En examinant attentivement les cinq V de la qualité des données, les investisseurs en capital-risque peuvent s’assurer qu’ils investissent dans des startups d’IA disposant des données dont elles ont besoin pour réussir. Si la startup peut répondre de manière convaincante aux questions ci-dessus et que ses données obtiennent des scores élevés dans les cinq dimensions, c'est un bon signe qu'elle prend au sérieux la qualité des données et qu'elle est suffisamment équipée pour appliquer ses modèles d'IA.
Enfin, les investisseurs en capital-risque devraient évaluer l'engagement de la startup en matière de sécurité des données. Cela inclut des éléments tels que vos politiques de gouvernance des données, vos procédures d’assurance qualité des données et vos plans de réponse aux violations de données.
Questionner le marché pour trouver les gagnants
Au milieu du buzz retentissant autour de l’IA ces derniers temps, l’attrait d’investissements substantiels a attiré les fondateurs de startups prêts à surestimer leur infrastructure et à gonfler leurs capacités dans la recherche de capitaux.
Les investisseurs en capital-risque qui réussissent posent les bonnes questions pour interroger ces entreprises de manière approfondie et filtrer les gagnants potentiels bâtis sur des bases solides parmi ceux qui ont une coquille creuse et qui sont finalement voués à l'échec. échec.

{kind=link}