



Von der Betrugserkennung bis zur Überwachung landwirtschaftlicher Nutzpflanzen ist eine neue Welle von Technologieunternehmen entstanden, die alle davon überzeugt sind, dass der Einsatz von KI die Herausforderungen der modernen Welt bewältigen wird.
Mit zunehmender Reife der KI-Landschaft kommt jedoch eine wachsende Sorge zum Vorschein: Im Herzen vieler KI-Unternehmen ihre Modelle, werden schnell zur Ware. Der bemerkenswerte Mangel an substanzieller Differenzierung zwischen diesen Modellen wirft allmählich Fragen über die Nachhaltigkeit ihres Wettbewerbsvorteils auf.
Während KI-Modelle weiterhin grundlegende Bestandteile dieser Unternehmen bleiben, findet ein Paradigmenwechsel statt. Das wahre Wertversprechen von KI-Unternehmen liegt mittlerweile nicht nur in den Modellen, sondern vor allem auch in den ihnen zugrunde liegenden Datensätzen. Es ist die Qualität, Breite und Tiefe dieser Datensätze, die es den Modellen ermöglicht, ihre Konkurrenten in den Schatten zu stellen.
Im Ansturm auf den Markt starten jedoch viele KI-gesteuerte Unternehmen, darunter auch solche, die sich in den vielversprechenden Bereich der Biotechnologie wagen, ohne die strategische Implementierung eines speziell entwickelten Technologie-Stacks, der die unverzichtbaren benötigten Daten generiert. für a automatisches Lernen solide. Dieses Versehen hat erhebliche Auswirkungen auf die Langlebigkeit Ihrer KI-Initiativen.
Wie Sie wissen Risikokapitalgeber (VC)-Experten reicht es nicht aus, die oberflächliche Attraktivität eines KI-Modells zu untersuchen. Stattdessen ist eine umfassende Bewertung der Technologie des Unternehmens erforderlich, um deren Eignung für den Zweck zu beurteilen. Das Fehlen einer sorgfältig konzipierten Infrastruktur für die Datenerfassung und -verarbeitung könnte frühzeitig den Untergang eines ansonsten vielversprechenden Unternehmens signalisieren.
Dieser Artikel bietet praktische Frameworks, die aus Erfahrungen mit Start-ups mit maschinellem Lernen abgeleitet wurden. Sie erheben keinen Anspruch auf Vollständigkeit, können aber eine zusätzliche Ressource für diejenigen sein, die vor der schwierigen Aufgabe stehen, die Datenprozesse von Unternehmen und die Qualität der daraus resultierenden Daten zu bewerten und letztendlich festzustellen, ob sie für den Erfolg gerüstet sind.
Was könnte schief gehen, von inkonsistenten Datensätzen bis hin zu verrauschten Eingaben?
Bevor wir zu den Frameworks übergehen, wollen wir zunächst die grundlegenden Faktoren bewerten, die bei der Bewertung der Datenqualität eine Rolle spielen. Und vor allem, was dabei herauskommen könnte schlecht, wenn die Daten Sie sind nicht auf dem neuesten Stand.
Relevanz
Betrachten wir zunächst die Relevanz der Datensätze. Die Daten müssen eng mit dem Problem übereinstimmen, das ein KI-Modell zu lösen versucht. Beispielsweise benötigt ein KI-Modell, das zur Vorhersage von Immobilienpreisen entwickelt wurde, Daten zu Wirtschaftsindikatoren, Zinssätzen, Realeinkommen und demografischen Veränderungen.
Ebenso ist es im Zusammenhang mit der Arzneimittelentwicklung von entscheidender Bedeutung, dass experimentelle Daten die größtmögliche Vorhersagbarkeit der Wirkungen bei Patienten zeigen, was eine fachmännische Reflexion relevanter Tests, Zelllinien, Modellorganismen und anderer erfordert.
Exactitud
Zweitens müssen die Daten korrekt sein. Selbst eine kleine Menge ungenauer Daten kann erhebliche Auswirkungen auf die Leistung eines KI-Modells haben. Dies ist besonders wichtig bei medizinischen Diagnosen, bei denen ein kleiner Fehler in den Daten zu einer Fehldiagnose führen und möglicherweise lebensgefährliche Folgen haben könnte.
Zielgruppe
Drittens ist auch die Datenabdeckung unerlässlich. Fehlen den Daten wichtige Informationen, kann das KI-Modell nicht so effektiv lernen. Wenn beispielsweise ein KI-Modell zur Übersetzung einer bestimmten Sprache verwendet wird, ist es wichtig, dass die Daten eine Vielzahl verschiedener Dialekte umfassen.
Bei Sprachmodellen wird dies als „ressourcenarmer“ gegenüber „ressourcenreichem“ Sprachdatensatz bezeichnet. Dies erfordert auch ein umfassendes Verständnis der Störfaktoren, die das Ergebnis beeinflussen, was in der Regel die Erfassung von Metadaten erfordert.
Vorurteile und Vorurteile
Schließlich verdient auch die Datenverzerrung eine gründliche Betrachtung. Die Daten müssen unvoreingenommen erfasst werden, um menschliche Voreingenommenheit oder Modellvoreingenommenheit zu vermeiden. Beispielsweise sollen Bilderkennungsdaten Stereotypisierungen minimieren. Bei der Arzneimittelforschung sollten Datensätze sowohl erfolgreiche als auch erfolglose Moleküle abdecken, um verzerrte Ergebnisse zu vermeiden. In beiden Fällen würden die Daten als verzerrt betrachtet und würden wahrscheinlich ihre Fähigkeit verlieren, neuartige Vorhersagen zu treffen.
Die Auswirkungen schlechter Daten sollten nicht unterschätzt werden. Im besten Fall führen sie dazu, dass das Modell leistungsschwach ist, und im schlimmsten Fall machen sie es völlig wirkungslos. Dies kann zu finanziellen Verlusten, verpassten Chancen und sogar körperlichen Schäden führen.
Wenn die Daten verzerrt sind, liefern die Modelle ebenfalls verzerrte Ergebnisse, was zu Diskriminierung und unlauteren Praktiken führen kann. Dies ist besonders besorgniserregend im Fall großer Sprachmodelle, die in letzter Zeit wegen der Aufrechterhaltung von Stereotypen in die Kritik geraten sind.
Eine beeinträchtigte Datenqualität birgt auch das Potenzial, die effektive Entscheidungsfindung zu beeinträchtigen, was letztendlich zu einer schlechten Geschäftsleistung führen kann.
Framework 1: Technologische Pyramide zur Datengenerierung
Um Investitionen in ineffektive KI-Startups zu vermeiden, ist es notwendig, zunächst die Prozesse hinter den Daten zu bewerten. Ein guter Ausgangspunkt ist es, sich das technologische Fundament eines Unternehmens als Pyramide vorzustellen, wobei die fundamentalen Ebenen tendenziell den größten Einfluss auf das Prognoseergebnis haben. Ohne diese solide Grundlage stoßen selbst die besten Datenanalyse- und maschinellen Lernmodelle auf erhebliche Einschränkungen.
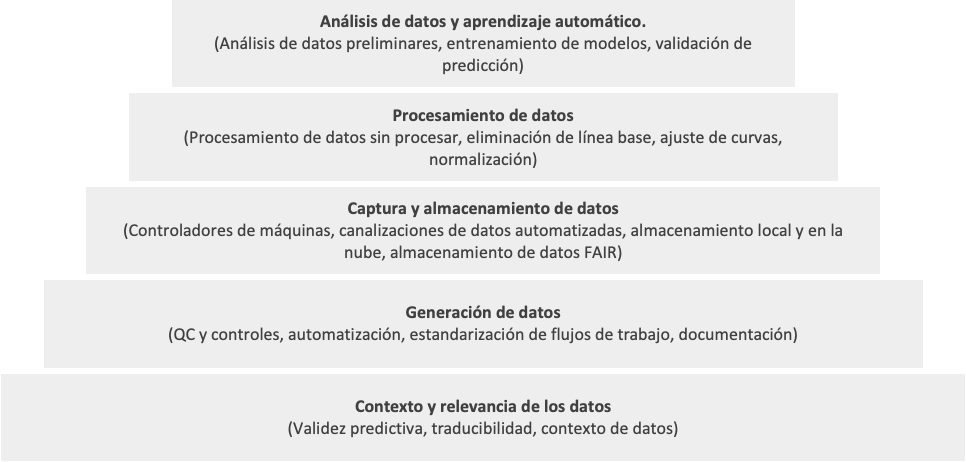
Hier sind einige grundlegende Fragen, die ein VC zunächst stellen könnte, um festzustellen, ob der Datengenerierungsprozess eines Startups tatsächlich brauchbare Ergebnisse für die KI liefern kann:
- Ist die Datenerfassung automatisiert, um eine Skalierung zu ermöglichen?
- Werden Daten in sicheren Cloud-Umgebungen mit automatisierten Backups gespeichert?
- Wie wird der Zugriff auf relevante IT-Ressourcen und Infrastruktur verwaltet und sichergestellt?
- Sind Datenverarbeitungsprozesse vollständig automatisiert und sind strenge Datenqualitätsprüfungen vorhanden, um die Kontamination durch kontaminierte Datenpunkte zu begrenzen?
- Sind Daten im gesamten Unternehmen leicht zugänglich, um Modelle für maschinelles Lernen und datengesteuerte Entscheidungen zu ermöglichen?
- Wie wird Data Governance umgesetzt?
- Gibt es eine Datenmanagementstrategie?
- Werden Versionen von Daten und ML-Modellen verfolgt und zugänglich gemacht, um sicherzustellen, dass ML-Modelle immer mit der neuesten Datenversion funktionieren?
Solide Antworten auf diese Fragen können dazu beitragen, das Verständnis eines Unternehmens über die zugrunde liegenden Prinzipien seiner Datenpipelines zu ermitteln. Dieses Verständnis wiederum wird dazu beitragen, die Qualität der Modellausgabe zu messen.
Framework 2: Die fünf Vs der Datenqualität
Sobald die technologische Grundlage eines Unternehmens für KI geeignet erachtet wird, muss es auch die Qualität der daraus resultierenden Daten, die zum Trainieren seiner Modelle verwendet werden, sorgfältig prüfen. Ein gängiger Rahmen zur Erfassung der Datenqualitätsklassifizierung sind die fünf Vs der Datenqualität. Sie stellen fünf Schlüsseldimensionen der Datenqualität dar, die Risikokapitalgeber bei der Bewertung von KI-Startups berücksichtigen sollten:
- Richtigkeit: Die Daten müssen korrekt und wahrheitsgetreu sein.
- Vielfalt: Die Daten sollten vielfältig und repräsentativ für die reale Welt sein.
- Volumen: Die Daten müssen groß genug sein, um das KI-Modell effektiv trainieren zu können.
- Geschwindigkeit: Daten müssen regelmäßig aktualisiert werden, um Veränderungen in der Welt widerzuspiegeln.
- Wert: Die Daten müssen nützlich sein, damit das KI-Modell daraus lernen kann.
Hier sind einige einführende Fragen, die bei der Bewertung der Daten eines Unternehmens für die fünf Vs helfen sollen:
- Hat das Startup eine gute Hypothese darüber, welche Daten es erstellen muss, um eine differenzierte Fähigkeit oder ein nützliches Modell aufzubauen?
- Welche Daten sammeln sie?
- Sammeln sie auch relevante Metadaten?
- Wie stellen Sie die Genauigkeit und Konsistenz der von Ihnen erfassten Daten sicher?
- Wie will das Startup mit Datenverzerrungen umgehen?
- Sammeln Sie mehrere Beispiele für dieselbe Frage oder dasselbe Experiment?
- Wie nützlich sind diese Daten für das Produkt, das Sie erstellen?
- Was ist der Grund für die Erhebung dieser Daten?
- Haben Sie Beweise dafür, dass sich Ihre Vorhersagen durch das Sammeln und Verwenden dieser Daten verbessern? Wenn ja, wie korreliert die Datenmenge mit der Vorhersageverbesserung?
- Wie einfach ist es für einen Wettbewerber, dieselben Daten zu sammeln?
- Wie lange würden sie dafür brauchen und wie viel würde es sie kosten?
- Wie gut korreliert der von ihm vorhergesagte Indikator speziell für ein Biotech-Unternehmen mit einem klinisch relevanten Endpunkt? Gibt es Beweise dafür?
- Welchen Plan verfolgt das Startup, um die Qualität seiner Daten langfristig sicherzustellen?
- Wie will das Startup seine Daten vor unbefugtem Zugriff schützen?
- Wie will das Startup die Datenschutzbestimmungen einhalten?
Durch sorgfältige Berücksichtigung der fünf Vs der Datenqualität können Risikokapitalgeber sicherstellen, dass sie in KI-Startups investieren, die über die Daten verfügen, die sie für den Erfolg benötigen. Wenn das Startup die oben genannten Fragen überzeugend beantworten kann und seine Daten in allen fünf Dimensionen gut abschneiden, ist das ein gutes Zeichen dafür, dass es die Datenqualität ernst nimmt und für die Anwendung seiner KI-Modelle ausreichend gerüstet ist.
Schließlich sollten Risikokapitalgeber das Engagement des Startups für die Datensicherheit bewerten. Dazu gehören Dinge wie Ihre Data-Governance-Richtlinien, Ihre Datenqualitätssicherungsverfahren und Ihre Pläne zur Reaktion auf Datenschutzverletzungen.
Befragen Sie den Markt, um die Gewinner zu finden
Inmitten der großen Begeisterung für KI in letzter Zeit hat die Verlockung erheblicher Investitionen Startup-Gründer angezogen, die bereit sind, ihre Infrastruktur zu übertreiben und ihre Kapazitäten auf der Suche nach Kapital aufzublähen.
Erfolgreiche Risikokapitalgeber stellen die richtigen Fragen, um diese Unternehmen gründlich zu befragen und potenzielle Gewinner, die auf einem soliden Fundament basieren, aus denen mit einer hohlen Hülle herauszufiltern, die letztendlich zum Scheitern verurteilt sind. fracaso.

{kind=link}