



Acompanhar uma indústria que evolui tão rapidamente quanto a IA é uma tarefa difícil. Então, até que uma IA consiga fazer isso, aqui está este resumo dos tópicos recentes no mundo do aprendizado de máquina, junto com pesquisas e experimentos notáveis.
Deepmind
O laboratório de pesquisa e desenvolvimento de IA de propriedade do Google, Deepmind, lançou um documento no qual propõe uma estrutura para avaliar os riscos sociais e éticos dos sistemas de IA.
O momento do seu lançamento, que requer vários níveis de envolvimento dos criadores de IA, dos criadores de aplicações e das “partes interessadas do público em geral” na avaliação e auditoria da IA, não é acidental.
Logo o Cúpula de Segurança de IA, um evento patrocinado pelo governo do Reino Unido que reunirá governos internacionais, empresas líderes em IA, grupos da sociedade civil e especialistas em investigação para se concentrarem na melhor forma de gerir os riscos dos mais recentes avanços em IA. incluindo IA generativa (por exemplo, ChatGPT, difusão estável, etc.). O Reino Unido é planejamento introduzir um grupo consultivo global sobre IA, inspirado no Painel Intergovernamental das Nações Unidas sobre Alterações Climáticas, composto por um elenco rotativo de académicos que escreverão relatórios regulares sobre desenvolvimentos de ponta em IA e os perigos associados.
A DeepMind está expressando sua perspectiva, de forma muito visível, antes das negociações políticas locais nesta cúpula de dois dias. E, para dar crédito a quem o merece, o laboratório de investigação levanta alguns pontos razoáveis (embora óbvios), tais como apelar a abordagens para examinar sistemas de IA no "ponto de interacção humana" e as formas como estes sistemas poderiam ser utilizados e o impacto na sociedade.
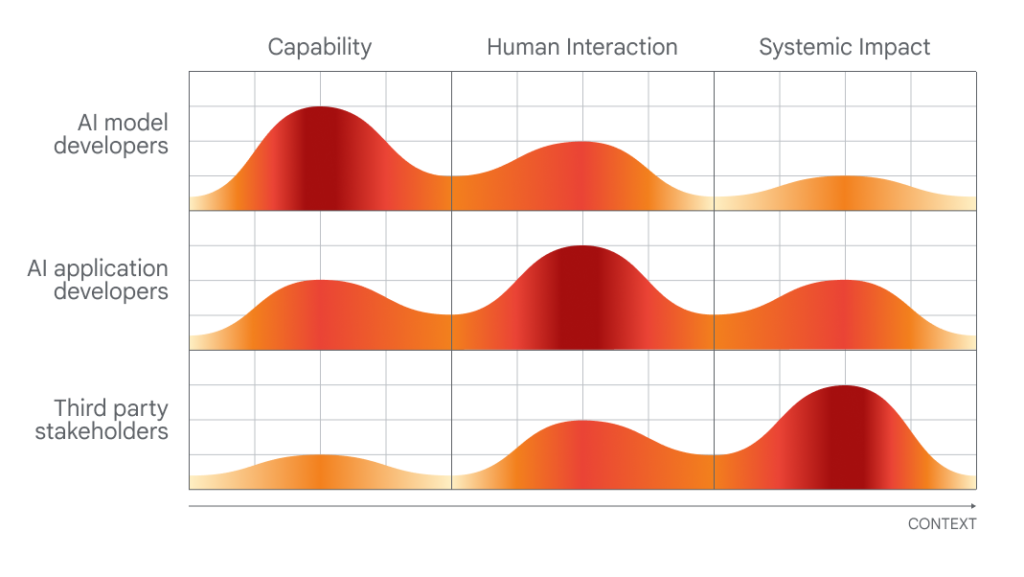
Gráfico mostrando quais pessoas seriam melhores em avaliar quais aspectos da IA.
Mas ao avaliar as propostas da DeepMind, é informativo observar a pontuação da empresa-mãe do laboratório, Google, em um estudo publicado por pesquisadores de Stanford que classifica os dez principais modelos de IA com base em seu grau de abertura.
Avaliado com base em 100 critérios, incluindo se o fabricante divulgou as fontes de seus dados de treinamento, informações sobre o hardware usado, o trabalho envolvido no treinamento e outros detalhes, o PaLM 2, um dos principais modelos de IA de análise de texto do Google, recebe um pobres 40%.%.
Agora, a DeepMind não desenvolveu o PaLM 2, pelo menos não diretamente. Mas o laboratório historicamente não tem sido consistentemente transparente sobre os seus próprios modelos, e o facto de a sua empresa-mãe não cumprir as principais medidas de transparência sugere que não há muita pressão de cima para baixo para que a DeepMind faça melhor.
Por outro lado, além das suas reflexões sobre políticas públicas, a DeepMind parece estar a tomar medidas para mudar a percepção de que é silenciosa sobre as arquitecturas e o funcionamento interno dos seus modelos. O laboratório, juntamente com a OpenAI e a Anthropic, comprometeu-se há vários meses a fornecer ao governo do Reino Unido “acesso antecipado ou prioritário” aos seus modelos de IA para apoiar a avaliação e a investigação de segurança.
A questão é: isso é meramente informativo? Afinal de contas, ninguém acusaria o DeepMind de filantropia: o laboratório fatura centenas de milhões de dólares todos os anos, principalmente através do licenciamento interno do seu trabalho às equipas do Google.
Talvez o próximo grande teste ético do laboratório seja o Gemini, seu próximo chatbot de IA, que o CEO da DeepMind, Demis Hassabis, prometeu repetidamente que rivalizará com o ChatGPT da OpenAI em seus recursos. Se a DeepMind quiser ser levada a sério na frente ética da IA, terá que detalhar completa e minuciosamente as fraquezas e limitações do Gemini, não apenas os seus pontos fortes. Certamente estaremos observando de perto para ver como as coisas evoluem nos próximos meses.
Em outras notícias
Aqui estão algumas outras histórias notáveis de IA:
- Estudo da Microsoft encontra falhas no GPT-4: Um novo artigo científico associado à Microsoft analisou a “confiabilidade” (e toxicidade) de grandes modelos de linguagem (LLMs), incluindo o GPT-4 da OpenAI. Os coautores descobriram que uma versão mais antiga do GPT-4 pode receber respostas mais facilmente do que outros LLMs que produzem textos tóxicos e tendenciosos.
- ChatGPT realiza pesquisas na web e DALL-E 3: sobre OpenAI, a empresa lançou formalmente seu recurso de navegação na Internet para ChatGPT, alguns três semanas após a reintrodução do recurso em beta após vários meses de hiato. Em notícias relacionadas, a OpenAI também fez a transição de DALL-E3 para beta, um mês após o lançamento da última encarnação do gerador de texto para imagem.
- Desafiadores GPT-4V: A OpenAI deve lançar em breve o GPT-4V, uma variante do GPT-4 que entende imagens e texto. Mas duas alternativas de código aberto vão direto ao ponto: LLaVA-1.5 e Fuyu-8B, um modelo de startup bem financiada perito. Nenhum deles é tão capaz quanto o GPT-4V, mas ambos chegam perto e, mais importante, são de uso gratuito.
- A IA pode jogar Pokémon?: Nos últimos anos, um engenheiro de software baseado em Seattle Peter Whidden vem treinando um algoritmo de aprendizado por reforço para navegar no primeiro jogo clássico da série Pokémon. Atualmente, ele chega apenas a Cerulean City, mas Whidden está confiante de que continuará melhorando.
- Tutor de idiomas com tecnologia de IA: O Google está segmentando Duolingo com um novo recurso de Pesquisa Google projetado para ajudar as pessoas a praticar (e melhorar) suas habilidades de falar inglês. O novo recurso, que será lançado nos próximos dias para dispositivos Android em países selecionados, proporcionará prática interativa de conversação para alunos de idiomas que traduzem de ou para o inglês.
- Amazon lança mais robôs de armazém: em um evento, Amazon anunciado que começará a testar o robô bípede Agility em suas instalações, Dígito. No entanto, lendo nas entrelinhas, não há garantia de que a Amazon realmente começará a implementar o Digit em seus armazéns, que atualmente utilizam mais de 750.000 sistemas robóticos.
- Simuladores sobre simuladores: Na mesma semana em que a Nvidia demonstrou como aplicar um LLM para ajudar a escrever código de aprendizado por reforço para guiar um robô ingênuo movido por IA a executar melhor uma tarefa, Meta lançou Habitat 3.0. A versão mais recente do conjunto de dados Meta para treinar agentes de IA em ambientes internos realistas. O Habitat 3.0 adiciona a possibilidade de avatares humanos compartilharem o espaço em realidade virtual.
- Os titãs da tecnologia da China investem na rival OpenAI: Zhipu AI, uma startup com sede na China que desenvolve modelos de IA para rivalizar com os da OpenAI e outros no espaço de IA generativa, anunciado que arrecadou 2.500 bilhões de yuans (US$ 340 milhões) em financiamento total até o momento este ano. O anúncio surge num momento em que as tensões geopolíticas entre os Estados Unidos e a China aumentam e não mostram sinais de diminuir.
- Os EUA sufocam o fornecimento de chips de IA da China: Sobre o tema das tensões geopolíticas, a administração Biden anunciou esta semana uma série de medidas para conter as ambições militares de Pequim, incluindo novas restrições ao envio de chips. Inteligencia artificial da Nvidia para a China. A800 e H800, os dois chips de IA que a Nvidia projetou especificamente para continuar a enviar para a China e que será afetado por essas novas regras.
- Replays de músicas pop da AI se tornam virais: aparece cobre uma tendência curiosa: contas tiktok que usam IA para fazer personagens como Homer Simpson cantarem músicas de rock dos anos 90 e 2000 como "Smells Like Teen Spirit”. Eles são divertidos superficialmente, mas há um tom sombrio em toda a prática.
Mais aprendizado de máquina
Os modelos de aprendizado de máquina levam consistentemente a avanços nas ciências da vida. AlphaFold e RoseTTAFold foram exemplos de como um problema persistente (dobramento de proteínas) poderia, de fato, ser banalizado com o modelo de IA correto. Agora, David Baker (criador deste último modelo) e os seus colegas de laboratório expandiram o processo de previsão para incluir mais do que apenas a estrutura das cadeias de aminoácidos relevantes. Afinal, as proteínas existem numa sopa de outras moléculas e átomos, e prever como irão interagir com compostos ou elementos perdidos no corpo é essencial para compreender a sua forma e actividade reais. RoseTTAFold All-Atom É um grande avanço para a simulação de sistemas biológicos.
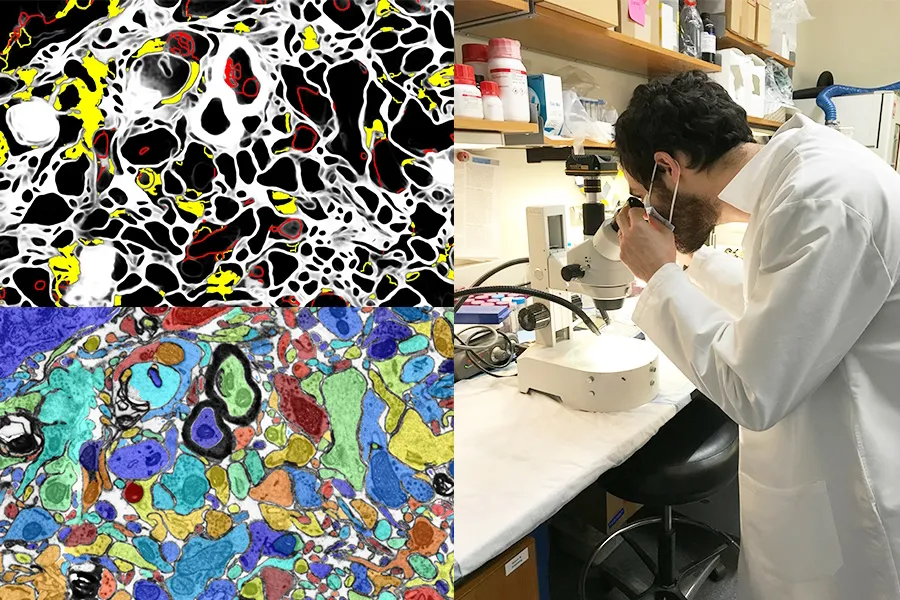
MIT/Universidade de Harvard
Ter IA visual que aprimore o trabalho de laboratório ou atue como uma ferramenta de aprendizagem também é uma grande oportunidade. O projeto SmartEM do MIT e Harvard coloca um sistema de visão computacional e um sistema de controle de ML dentro de um microscópio eletrônico de varredura, que juntos conduzem o dispositivo para examinar uma amostra de forma inteligente. Você pode evitar áreas de baixa importância, focar em áreas interessantes ou claras e também rotular de forma inteligente a imagem resultante.
Usar IA e outras ferramentas de alta tecnologia para fins arqueológicos nunca sai de moda (por assim dizer). Quer se trate de um lidar (um sensor que emite pulsos de luz continuamente e captura seus retornos) revelando cidades e estradas maias ou preenchendo lacunas de textos gregos antigos incompletos, é sempre interessante observar. E esta reconstrução de um pergaminho que se pensa ter sido destruído na erupção vulcânica que devastou Pompeia é uma das mais impressionantes até agora.

Tomografia computadorizada interpretada por ML de um papiro enrolado e queimado. A palavra visível diz “Roxo”.
Luke Farritor, estudante de ciência da computação da Universidade de Nebraska-Lincoln, treinou um modelo de aprendizado de máquina para amplificar padrões sutis em digitalizações do papiro enrolado e carbonizado que são invisíveis a olho nu. Esse foi um dos muitos métodos tentados em um desafio internacional para ler os pergaminhos e poderia ser refinado para trabalhos acadêmicos valiosos. A informação é publicado pela Natureza.. O que havia no pergaminho? Até agora, apenas a palavra “roxo”, mas mesmo isso faz os papirologistas enlouquecerem.
Outra vitória acadêmica da IA está em este sistema para examinar e sugerir citações na Wikipedia. É claro que a IA não sabe o que é verdadeiro ou factual, mas pode extrair do contexto a aparência de um artigo e uma citação da Wikipedia de alta qualidade e procurar alternativas no site e na web. Ninguém está sugerindo que deixemos robôs executarem a famosa enciclopédia on-line dirigida ao usuário, mas isso poderia ajudar a reforçar artigos para os quais faltam citações ou os editores não têm certeza.

Exemplo de problema matemático resolvido por Llemma.
Os modelos de linguagem podem ser ajustados em muitos tópicos e, surpreendentemente, a matemática avançada é um deles. Llemma é um novo modelo aberto preparado para testes matemáticos e artigos que podem resolver problemas bastante complexos. Não é o primeiro: Minerva, do Google Research, está trabalhando em capacidades semelhantes, mas seu sucesso em conjuntos de problemas semelhantes e maior eficiência mostram que modelos “abertos” (seja qual for o termo) são competitivos neste espaço. É indesejável que certos tipos de IA sejam dominados por modelos proprietários, pelo que a replicação aberta das suas capacidades é valiosa, mesmo que não abra novos caminhos.
É preocupante que Meta esteja a fazer progressos no seu próprio trabalho académico no sentido da leitura da mente, mas como acontece com a maioria dos estudos nesta área, a forma como é apresentado exagera o processo. Em um artigo intitulado “Decodificação cerebral: rumo à reconstrução em tempo real da percepção visual”, Pode parecer que eles estão lendo mentes.

Imagens mostradas às pessoas (esquerda) e IA generativa adivinha o que a pessoa está percebendo (direita).
Mas é um pouco mais indireto do que isso. Ao estudar a aparência de uma tomografia cerebral de alta frequência quando as pessoas olham imagens de certas coisas, como cavalos ou aviões, os pesquisadores podem fazer reconstruções quase em tempo real do que acham que a pessoa está pensando ou olhando. Ainda assim, parece provável que a IA generativa tenha um papel a desempenhar aqui, na forma como pode criar uma expressão visual de algo, mesmo que não corresponda diretamente às digitalizações.
¿Deveríamos Usar IA para ler a mente das pessoas, se algum dia for possível? Vamos perguntar ao DeepMind (veja acima).
Finalmente, um projeto em LAION que neste momento é mais aspiracional do que concreto, mas igualmente louvável. A Aprendizagem Contrastiva Multilíngue para Aquisição de Representação de Áudio, ou CLARA, visa dar aos modelos de linguagem uma melhor compreensão das nuances da fala humana. Sabemos como o sarcasmo ou uma mentira podem ser detectados a partir de sinais subverbais, como tom ou pronúncia? As máquinas são muito ruins nisso, o que é uma má notícia para qualquer interação humano-IA. CLARA utiliza uma biblioteca de áudio e texto multilíngue para identificar alguns estados emocionais e outras pistas não-verbais de “compreensão da fala”.

{kind=link}