



Da deteção de fraudes à monitorização de culturas agrícolas, surgiu uma nova vaga de empresas tecnológicas, todas armadas com a convicção de que a sua utilização da IA irá enfrentar os desafios apresentados pelo mundo moderno.
No entanto, à medida que o cenário da IA amadurece, uma preocupação crescente vem à tona: no coração de muitas empresas de IA, seus modelos, estão rapidamente se tornando commodities. Uma notável falta de diferenciação substancial entre estes modelos começa a levantar questões sobre a sustentabilidade da sua vantagem competitiva.
Em vez disso, embora os modelos de IA continuem a ser componentes fundamentais destas empresas, está a ocorrer uma mudança de paradigma. A verdadeira proposta de valor das empresas de IA reside agora não apenas nos modelos, mas também predominantemente nos conjuntos de dados que os sustentam. É a qualidade, amplitude e profundidade destes conjuntos de dados que permite que os modelos superem os seus concorrentes.
Sin embargo, en la prisa por llegar al mercado, muchas empresas impulsadas por la IA, incluidas aquellas que se aventuran en el prometedor campo de la biotecnología, se lanzan sin la implementación estratégica de una pila de tecnología especialmente diseñada que genere los datos indispensables necesarios para um aprendizado automático sólido. Esta supervisão tem implicações substanciais para a longevidade das suas iniciativas de IA.
Como você bem sabe capitalistas de risco (VC), não basta examinar o apelo superficial de um modelo de IA. Em vez disso, é necessária uma avaliação abrangente da tecnologia da empresa para avaliar a sua adequação ao propósito. A ausência de uma infra-estrutura meticulosamente concebida para aquisição e processamento de dados pode sinalizar antecipadamente a queda de uma empresa que de outra forma seria promissora.
Este artigo oferece estruturas práticas derivadas da experiência em startups habilitadas para aprendizado de máquina. Não são exaustivos, mas podem fornecer um recurso adicional para aqueles que têm a difícil tarefa de avaliar os processos de dados das empresas e a qualidade dos dados resultantes e, em última análise, determinar se estão preparados para o sucesso.
De conjuntos de dados inconsistentes a entradas ruidosas, o que poderia dar errado?
Antes de passarmos para as estruturas, vamos primeiro avaliar os fatores básicos que entram em jogo na avaliação da qualidade dos dados. E, acima de tudo, o que poderia sair ruim se os dados Eles não estão à altura.
Relevância
Primeiro, vamos considerar a relevância dos conjuntos de dados. Os dados devem estar intrinsecamente alinhados com o problema que um modelo de IA está tentando resolver. Por exemplo, um modelo de IA desenvolvido para prever os preços da habitação necessita de dados que abranjam indicadores económicos, taxas de juro, rendimentos reais e alterações demográficas.
Da mesma forma, no contexto da descoberta de medicamentos, é crucial que os dados experimentais mostrem a maior previsibilidade possível dos efeitos nos pacientes, exigindo reflexão especializada sobre ensaios relevantes, linhas celulares, organismos modelo e outros.
exactitud
Em segundo lugar, os dados devem ser precisos. Mesmo uma pequena quantidade de dados imprecisos pode ter um impacto significativo no desempenho de um modelo de IA. Isto é especialmente crítico em diagnósticos médicos, onde um pequeno erro nos dados pode levar a um diagnóstico errado e potencialmente afetar vidas.
Cobertura
Terceiro, a cobertura de dados também é essencial. Se faltarem informações importantes nos dados, o modelo de IA não será capaz de aprender de forma tão eficaz. Por exemplo, se um modelo de IA for usado para traduzir um idioma específico, é importante que os dados incluam uma variedade de dialetos diferentes.
Para modelos de linguagem, isso é conhecido como conjunto de dados de linguagem de “baixos recursos” versus “altos recursos”. Isto também requer uma compreensão completa dos factores de confusão que afectam o resultado, o que normalmente requer a recolha de metadados.
Viés e preconceitos
Finalmente, o viés de dados também merece consideração rigorosa. Os dados devem ser capturados de maneira imparcial para evitar preconceitos humanos ou preconceitos de modelo. Por exemplo, os dados de reconhecimento de imagem devem minimizar os estereótipos. Na descoberta de medicamentos, os conjuntos de dados devem abranger moléculas bem-sucedidas e malsucedidas para evitar resultados tendenciosos. Em ambos os casos, os dados seriam considerados tendenciosos e provavelmente perderiam a sua capacidade de fazer novas previsões.
O impacto de dados deficientes não deve ser subestimado. Na melhor das hipóteses, resultam num modelo de baixo desempenho e, na pior, tornam-no completamente ineficaz. Isso pode levar a perdas financeiras, oportunidades perdidas e até danos físicos.
Da mesma forma, se os dados forem tendenciosos, os modelos produzirão resultados tendenciosos, o que pode encorajar a discriminação e práticas injustas. Esta tem sido uma preocupação particular no caso de grandes modelos linguísticos, que recentemente foram alvo de escrutínio por perpetuarem estereótipos.
A qualidade dos dados comprometida também tem o potencial de prejudicar a tomada de decisões eficaz, o que pode, em última análise, resultar num fraco desempenho empresarial.
Quadro 1: Pirâmide tecnológica para geração de dados
Para evitar investir em startups de IA ineficazes, é necessário primeiro avaliar os processos por trás dos dados. Imaginar a base tecnológica de uma empresa como uma pirâmide é um bom ponto de partida, onde os níveis fundamentais tendem a ter o maior impacto no resultado preditivo. Sem esta base sólida, mesmo os melhores modelos de análise de dados e aprendizagem automática enfrentam limitações significativas.
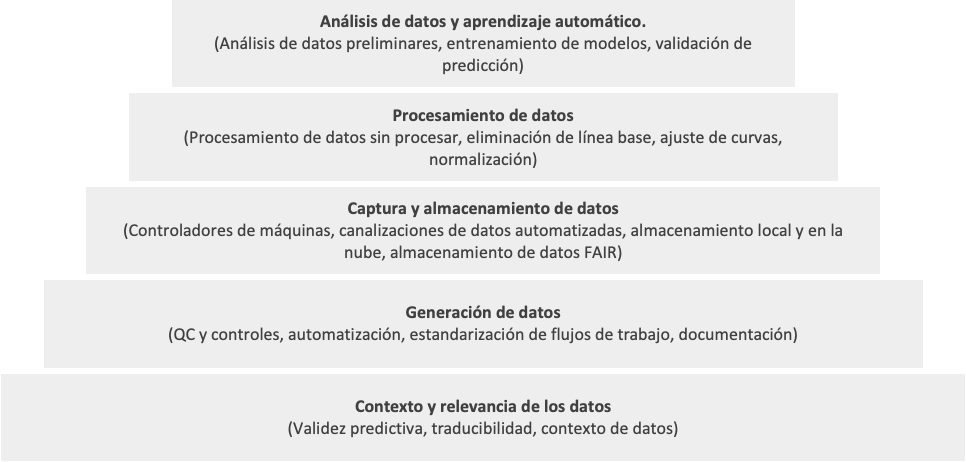
Aqui estão algumas perguntas básicas que um VC pode fazer inicialmente para determinar se o processo de geração de dados de uma startup pode realmente criar resultados utilizáveis para IA:
- A captura de dados é automatizada para permitir o dimensionamento?
- Os dados são armazenados em ambientes de nuvem seguros com backups automatizados?
- Como é gerido e garantido o acesso aos recursos e infraestruturas de TI relevantes?
- Os processos de processamento de dados são totalmente automatizados, com verificações rigorosas de qualidade dos dados para limitar a contaminação de pontos de dados contaminados?
- Os dados são facilmente acessíveis em toda a empresa para potencializar modelos de aprendizado de máquina e decisões baseadas em dados?
- Como a governança de dados é implementada?
- Existe uma estratégia de gerenciamento de dados?
- As versões dos dados e modelos de ML são rastreadas e acessíveis, garantindo que os modelos de ML sempre funcionem com a versão mais recente dos dados?
Receber respostas sólidas a estas perguntas pode ajudar a determinar a compreensão de uma empresa sobre os princípios subjacentes aos seus pipelines de dados. Essa compreensão, por sua vez, ajudará a medir a qualidade do resultado do modelo.
Estrutura 2: Os cinco Vs da qualidade dos dados
Uma vez que a base tecnológica de uma empresa é considerada adequada para IA, ela também precisa considerar cuidadosamente a qualidade dos dados resultantes usados para treinar seus modelos. Uma estrutura comum usada para capturar a classificação da qualidade dos dados são os cinco Vs da qualidade dos dados. Representam cinco dimensões principais da qualidade dos dados que os capitalistas de risco devem considerar ao avaliar startups de IA:
- Veracidade: Os dados devem ser precisos e verdadeiros.
- Variedade: Os dados devem ser diversos e representativos do mundo real.
- Volume: Os dados devem ser grandes o suficiente para treinar o modelo de IA de forma eficaz.
- Velocidade: Os dados devem ser atualizados frequentemente para refletir as mudanças no mundo.
- Valor: Os dados devem ser úteis para que o modelo de IA possa aprender com eles.
Aqui estão algumas perguntas introdutórias para ajudar a avaliar os dados de uma empresa quanto aos cinco Vs:
- A startup tem uma boa hipótese sobre quais dados precisa criar para construir uma capacidade diferenciada ou um modelo útil?
- Que dados eles coletam?
- Eles também coletam metadados relevantes?
- Como você garante a precisão e a consistência dos dados coletados?
- Como a startup planeja lidar com o viés de dados?
- Você coleta vários exemplos para a mesma pergunta ou experimento?
- Quão úteis são esses dados para o produto que você está criando?
- Qual é a razão por trás da coleta desses dados?
- Você tem evidências de que suas previsões melhoram com a coleta e o uso desses dados? Em caso afirmativo, como a quantidade de dados se correlaciona com a melhoria da previsão?
- Quão fácil é para um concorrente coletar os mesmos dados?
- Quanto tempo levariam e quanto lhes custaria para fazer isso?
- Especificamente para uma empresa de biotecnologia, até que ponto o indicador que eles prevêem se correlaciona com um desfecho clinicamente relevante? Há evidências disso?
- Qual o plano da startup para garantir a qualidade dos seus dados ao longo do tempo?
- Como a startup planeja proteger seus dados contra acesso não autorizado?
- Como a startup planeja cumprir os regulamentos de privacidade de dados?
Ao considerar cuidadosamente os cinco Vs da qualidade dos dados, os capitalistas de risco podem garantir que estão investindo em startups de IA que possuem os dados necessários para ter sucesso. Se a startup puder responder às perguntas acima de forma convincente e seus dados obtiverem pontuações altas em todas as cinco dimensões, é um bom sinal de que ela leva a sério a qualidade dos dados e está adequadamente equipada para aplicar seus modelos de IA.
Finalmente, os capitalistas de risco devem avaliar o compromisso da startup com a segurança dos dados. Isso inclui coisas como políticas de governança de dados, procedimentos de garantia de qualidade de dados e planos de resposta a violações de dados.
Questione o mercado para encontrar os vencedores
No meio do burburinho retumbante em torno da IA ultimamente, a atração de investimentos substanciais atraiu fundadores de startups dispostos a exagerar na sua infraestrutura e a aumentar as capacidades na procura de capital.
Os capitalistas de risco bem-sucedidos estão a fazer as perguntas certas para interrogar estas empresas minuciosamente e a filtrar os potenciais vencedores construídos sobre uma base sólida daqueles com uma casca vazia que estão, em última análise, destinados ao fracasso. fracaso.

{kind=link}