



Dal rilevamento delle frodi al monitoraggio delle colture agricole, è emersa una nuova ondata di aziende tecnologiche, tutte armate della convinzione che il loro utilizzo dell’intelligenza artificiale affronterà le sfide presentate dal mondo moderno.
Tuttavia, man mano che il panorama dell’intelligenza artificiale matura, sta emergendo una preoccupazione crescente: al centro di molte aziende di intelligenza artificiale, i loro modelli, stanno rapidamente diventando merci. Una notevole mancanza di differenziazione sostanziale tra questi modelli sta cominciando a sollevare interrogativi sulla sostenibilità del loro vantaggio competitivo.
Invece, mentre i modelli di intelligenza artificiale rimangono componenti fondamentali di queste aziende, si sta verificando un cambiamento di paradigma. La vera proposta di valore delle aziende di intelligenza artificiale ora non risiede solo nei modelli, ma soprattutto nei set di dati che li sostengono. È la qualità, l’ampiezza e la profondità di questi set di dati che consente ai modelli di surclassare quelli della concorrenza.
Tuttavia, nella corsa al mercato, molte aziende guidate dall’intelligenza artificiale, comprese quelle che si avventurano nel promettente campo della biotecnologia, si lanciano senza l’implementazione strategica di uno stack tecnologico appositamente creato che generi i dati indispensabili necessari. apprendimento automatico solido. Questa supervisione ha implicazioni sostanziali per la longevità delle vostre iniziative di intelligenza artificiale.
Come ben sai capitalisti di ventura (VC), non è sufficiente esaminare l’attrattiva superficiale di un modello di intelligenza artificiale. È invece necessaria una valutazione completa della tecnologia dell’azienda per valutarne l’idoneità allo scopo. L’assenza di un’infrastruttura meticolosamente progettata per l’acquisizione e l’elaborazione dei dati potrebbe segnalare precocemente il fallimento di un’azienda altrimenti promettente.
Questo articolo offre strutture pratiche derivate dall'esperienza nelle startup abilitate al machine learning. Non sono esaustivi, ma possono fornire una risorsa aggiuntiva per coloro che hanno il difficile compito di valutare i processi di dati delle aziende e la qualità dei dati risultanti e, in definitiva, determinare se sono pronti per il successo.
Da set di dati incoerenti a input rumorosi, cosa potrebbe andare storto?
Prima di passare ai framework, valutiamo innanzitutto i fattori fondamentali che entrano in gioco nella valutazione della qualità dei dati. E, soprattutto, cosa potrebbe venir fuori male se i dati Non sono all'altezza.
Rilevanza
Innanzitutto, consideriamo la rilevanza dei set di dati. I dati devono essere strettamente allineati al problema che un modello di intelligenza artificiale sta cercando di risolvere. Ad esempio, un modello di intelligenza artificiale sviluppato per prevedere i prezzi delle case necessita di dati che coprano indicatori economici, tassi di interesse, redditi reali e cambiamenti demografici.
Allo stesso modo, nel contesto della scoperta di farmaci, è fondamentale che i dati sperimentali mostrino la massima prevedibilità possibile degli effetti nei pazienti, richiedendo una riflessione esperta su test rilevanti, linee cellulari, organismi modello e altri.
Precisione
In secondo luogo, i dati devono essere accurati. Anche una piccola quantità di dati imprecisi può avere un impatto significativo sulle prestazioni di un modello di intelligenza artificiale. Ciò è particolarmente critico nelle diagnosi mediche, dove un piccolo errore nei dati potrebbe portare a una diagnosi errata e potenzialmente influenzare la vita.
Copertura
In terzo luogo, anche la copertura dei dati è essenziale. Se nei dati mancano informazioni importanti, il modello AI non sarà in grado di apprendere in modo altrettanto efficace. Ad esempio, se un modello di intelligenza artificiale viene utilizzato per tradurre una particolare lingua, è importante che i dati includano una varietà di dialetti diversi.
Per i modelli linguistici, questo è noto come set di dati linguistici con “basse risorse” e “con risorse elevate”. Ciò richiede anche una comprensione completa dei fattori confondenti che influenzano il risultato, che in genere richiede la raccolta di metadati.
Pregiudizi e pregiudizi
Infine, anche la distorsione dei dati merita una considerazione rigorosa. I dati devono essere acquisiti in modo imparziale per evitare pregiudizi umani o distorsioni dei modelli. Ad esempio, i dati di riconoscimento delle immagini dovrebbero ridurre al minimo gli stereotipi. Nella scoperta di farmaci, i set di dati dovrebbero coprire sia le molecole riuscite che quelle infruttuose per evitare risultati distorti. In entrambi i casi, i dati sarebbero considerati distorti e probabilmente perderebbero la capacità di fare nuove previsioni.
L’impatto di dati scarsi non dovrebbe essere sottovalutato. Nella migliore delle ipotesi, si traducono in un modello poco performante e, nel peggiore dei casi, lo rendono completamente inefficace. Ciò può portare a perdite finanziarie, opportunità mancate e persino danni fisici.
Allo stesso modo, se i dati sono distorti, i modelli produrranno risultati distorti, che possono incoraggiare la discriminazione e le pratiche sleali. Ciò ha costituito una preoccupazione particolare nel caso dei modelli linguistici di grandi dimensioni, che recentemente sono stati oggetto di esame accurato per la perpetuazione di stereotipi.
La compromissione della qualità dei dati può anche compromettere l’efficacia del processo decisionale, il che, in ultima analisi, può portare a scarse prestazioni aziendali.
Framework 1: Piramide tecnologica per la generazione dei dati
Per evitare di investire in startup IA inefficaci, è necessario prima valutare i processi dietro i dati. Immaginare la base tecnologica di un'azienda come una piramide è un buon punto di partenza, in cui i livelli fondamentali tendono ad avere il maggiore impatto sul risultato predittivo. Senza queste solide basi, anche i migliori modelli di analisi dei dati e di machine learning si trovano ad affrontare limitazioni significative.
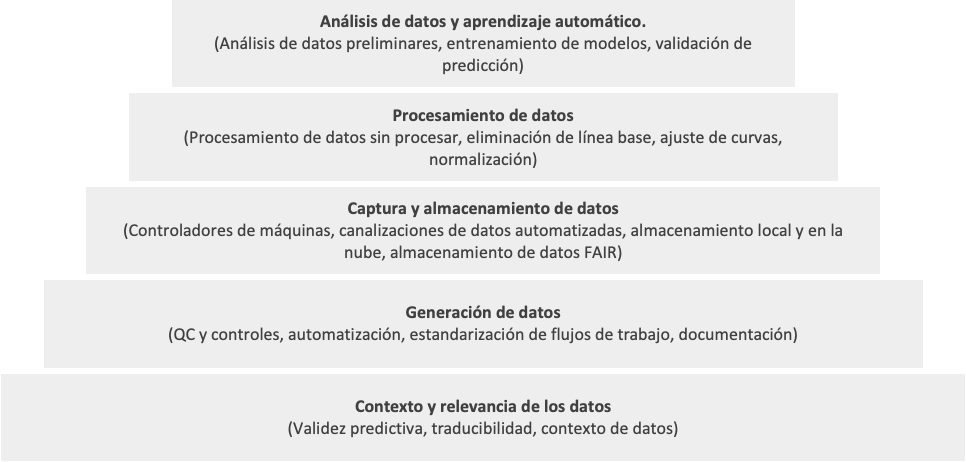
Ecco alcune domande di base che un VC potrebbe inizialmente porre per determinare se il processo di generazione dei dati di una startup può effettivamente creare risultati utilizzabili per l'intelligenza artificiale:
- L'acquisizione dei dati è automatizzata per consentire la scalabilità?
- I dati sono archiviati in ambienti cloud sicuri con backup automatizzati?
- Come viene gestito e garantito l'accesso alle risorse e alle infrastrutture IT pertinenti?
- I processi di elaborazione dei dati sono completamente automatizzati, con rigorosi controlli di qualità dei dati in atto per limitare la contaminazione da punti dati contaminati?
- I dati sono facilmente accessibili in tutta l’azienda per alimentare modelli di machine learning e decisioni basate sui dati?
- Come viene implementata la governance dei dati?
- Esiste una strategia di gestione dei dati?
- Le versioni dei dati e dei modelli ML vengono tracciate e accessibili, garantendo che i modelli ML funzionino sempre con la versione più recente dei dati?
Ricevere risposte concrete a queste domande può aiutare a determinare la comprensione da parte di un'azienda dei principi alla base delle sue pipeline di dati. Questa comprensione, a sua volta, aiuterà a misurare la qualità dell’output del modello.
Framework 2: Le cinque V della qualità dei dati
Una volta che la base tecnologica di un’azienda è ritenuta idonea all’intelligenza artificiale, è necessario considerare attentamente anche la qualità dei dati risultanti utilizzati per addestrare i propri modelli. Un quadro comune utilizzato per acquisire la classificazione della qualità dei dati sono le cinque V della qualità dei dati. Rappresentano cinque dimensioni chiave della qualità dei dati che i venture capitalist dovrebbero considerare quando valutano le startup AI:
- Veridicità: i dati devono essere accurati e veritieri.
- Varietà: i dati dovrebbero essere diversi e rappresentativi del mondo reale.
- Volume: i dati devono essere sufficientemente grandi per addestrare in modo efficace il modello AI.
- Velocità: i dati devono essere aggiornati frequentemente per riflettere i cambiamenti nel mondo.
- Valore: i dati devono essere utili affinché il modello di intelligenza artificiale possa trarne insegnamento.
Ecco alcune domande introduttive per aiutare a valutare i dati di un'azienda rispetto alle cinque V:
- La startup ha una buona ipotesi su quali dati deve creare per costruire una capacità differenziata o un modello utile?
- Quali dati raccolgono?
- Raccolgono anche metadati rilevanti?
- Come garantite l'accuratezza e la coerenza dei dati raccolti?
- In che modo la startup intende gestire la distorsione dei dati?
- Raccogli più esempi per la stessa domanda o esperimento?
- Quanto sono utili questi dati per il prodotto che stai creando?
- Qual è il motivo dietro la raccolta di questi dati?
- Hai prove che le tue previsioni migliorino raccogliendo e utilizzando questi dati? In tal caso, in che modo la quantità di dati è correlata al miglioramento della previsione?
- Quanto è facile per un concorrente raccogliere gli stessi dati?
- Quanto tempo impiegherebbero e quanto costerebbe loro farlo?
- Nello specifico per un'azienda biotecnologica, quanto bene l'indicatore previsto è correlato a un endpoint clinicamente rilevante? Ci sono prove di ciò?
- Qual è il piano della startup per garantire la qualità dei propri dati nel tempo?
- Come intende la startup proteggere i propri dati da accessi non autorizzati?
- Come intende la startup rispettare le normative sulla privacy dei dati?
Considerando attentamente le cinque V della qualità dei dati, i venture capitalist possono assicurarsi di investire in startup IA che dispongono dei dati di cui hanno bisogno per avere successo. Se la startup riesce a rispondere in modo convincente alle domande di cui sopra e i suoi dati ottengono punteggi elevati in tutte e cinque le dimensioni, è un buon segno che prende sul serio la qualità dei dati e è adeguatamente attrezzata per applicare i propri modelli di intelligenza artificiale.
Infine, i venture capitalist dovrebbero valutare l'impegno della startup nei confronti della sicurezza dei dati. Ciò include aspetti come le politiche di governance dei dati, le procedure di garanzia della qualità dei dati e i piani di risposta alla violazione dei dati.
Interrogare il mercato per trovare i vincitori
Nel clamoroso brusio che circonda l’intelligenza artificiale negli ultimi tempi, il richiamo di investimenti sostanziali ha attratto i fondatori di startup disposti a sovrastimare le loro infrastrutture e a gonfiare le capacità nella ricerca di capitale.
I venture capitalist di successo stanno ponendo le domande giuste per interrogare a fondo queste aziende e filtrando i potenziali vincitori costruiti su solide basi da quelli con un guscio vuoto che alla fine sono destinati al fallimento. fracaso.

{kind=link}