
Fundadores e Inversores
De la detección de fraude al monitoreo de cultivos agrícolas, ha surgido una nueva ola de empresas tecnológicas, todas armadas con la convicción de que su uso de la IA abordará los desafíos que presenta el mundo moderno.
Sin embargo, a medida que el panorama de la IA madura, sale a la luz una preocupación creciente: el corazón de muchas empresas de IA, sus modelos, se están convirtiendo rápidamente en mercancías. Una notable falta de diferenciación sustancial entre estos modelos está comenzando a plantear dudas sobre la sostenibilidad de su ventaja competitiva.
En cambio, si bien los modelos de IA siguen siendo componentes fundamentales de estas empresas, se está produciendo un cambio de paradigma. La verdadera propuesta de valor de las empresas de IA ahora no reside sólo en los modelos, sino también predominantemente en los conjuntos de datos que los sustentan. Es la calidad, amplitud y profundidad de estos conjuntos de datos lo que permite a los modelos eclipsar a sus competidores.
Sin embargo, en la prisa por llegar al mercado, muchas empresas impulsadas por la IA, incluidas aquellas que se aventuran en el prometedor campo de la biotecnología, se lanzan sin la implementación estratégica de una pila de tecnología especialmente diseñada que genere los datos indispensables necesarios para un aprendizaje automático sólido. Esta supervisión tiene implicaciones sustanciales para la longevidad de sus iniciativas de IA.
Como bien sabrán los capitalistas de riesgo (VC) experimentados, no basta con examinar el atractivo superficial de un modelo de IA. En cambio, se necesita una evaluación integral de la tecnología de la empresa para evaluar su idoneidad para su propósito. La ausencia de una infraestructura meticulosamente diseñada para la adquisición y el procesamiento de datos podría indicar desde el principio la caída de una empresa que de otro modo sería prometedora.
Este artículo, ofrece marcos prácticos derivados de la experiencia en startups habilitadas para el aprendizaje automático. No son exhaustivos, pero pueden proporcionar un recurso adicional para quienes tienen la difícil tarea de evaluar los procesos de datos de las empresas y la calidad de los datos resultantes y, en última instancia, determinar si están preparados para el éxito.
Desde conjuntos de datos inconsistentes hasta entradas ruidosas, ¿qué podría salir mal?
Antes de pasar a los marcos, primero evalúemos los factores básicos que entran en juego al evaluar la calidad de los datos. Y, sobre todo, qué podría salir mal si los datos no están a la altura.
Relevancia
Primero, consideremos la relevancia de los conjuntos de datos. Los datos deben alinearse intrincadamente con el problema que un modelo de IA intenta resolver. Por ejemplo, un modelo de IA desarrollado para predecir los precios de la vivienda necesita datos que abarquen indicadores económicos, tasas de interés, ingresos reales y cambios demográficos.
De manera similar, en el contexto del descubrimiento de fármacos, es crucial que los datos experimentales muestren la mayor capacidad de predicción posible de los efectos en los pacientes, lo que requiere una reflexión experta sobre los ensayos, líneas celulares, organismos modelo y otros relevantes.
Exactitud
En segundo lugar, los datos deben ser precisos. Incluso una pequeña cantidad de datos inexactos puede tener un impacto significativo en el rendimiento de un modelo de IA. Esto es especialmente crítico en los diagnósticos médicos, donde un pequeño error en los datos podría llevar a un diagnóstico erróneo y potencialmente afectar vidas.
Cobertura
En tercer lugar, la cobertura de datos también es esencial. Si a los datos les falta información importante, el modelo de IA no podrá aprender con tanta eficacia. Por ejemplo, si se utiliza un modelo de IA para traducir un idioma en particular, es importante que los datos incluyan una variedad de dialectos diferentes.
Para los modelos de lenguaje, esto se conoce como un conjunto de datos de lenguaje de “bajos recursos” versus “altos recursos”. Esto también requiere tener una comprensión completa de los factores de confusión que afectan el resultado, lo que normalmente requiere la recopilación de metadatos.
Sesgos y prejuicios
Finalmente, el sesgo de los datos también merece una consideración rigurosa. Los datos deben capturarse de manera imparcial para evitar prejuicios humanos o sesgos en el modelo. Por ejemplo, los datos de reconocimiento de imágenes deberían minimizar los estereotipos. En el descubrimiento de fármacos, los conjuntos de datos deben abarcar tanto moléculas exitosas como no exitosas para evitar resultados sesgados. En ambos casos, los datos se considerarían sesgados y probablemente perderían su capacidad de hacer predicciones novedosas.
No se deben subestimar las repercusiones de unos datos deficientes. En el mejor de los casos, dan como resultado un modelo con un rendimiento inferior y, en el peor, lo hacen completamente ineficaz. Esto puede provocar pérdidas financieras, oportunidades perdidas e incluso daños físicos.
De manera similar, si los datos están sesgados, los modelos producirán resultados sesgados, lo que puede fomentar la discriminación y prácticas injustas. Esto ha sido una preocupación particular en el caso de los grandes modelos lingüísticos, que recientemente han sido objeto de escrutinio por perpetuar estereotipos.
La calidad de los datos comprometida también tiene el potencial de erosionar la toma de decisiones efectiva, lo que en última instancia puede resultar en un desempeño empresarial deficiente.
Marco 1: Pirámide tecnológica para la generación de dato
Para evitar invertir en nuevas empresas de IA ineficaces, es necesario evaluar primero los procesos detrás de los datos. Imaginar la base tecnológica de una empresa como una pirámide es un buen punto de partida, donde los niveles fundamentales tienden a tener el mayor impacto en el resultado predictivo. Sin esta base sólida, incluso los mejores modelos de análisis de datos y aprendizaje automático enfrentan limitaciones importantes.
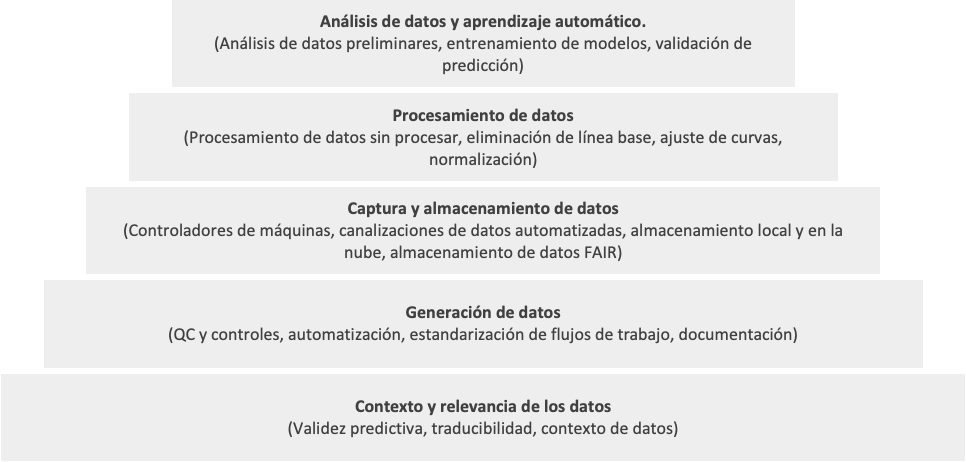
Aquí hay algunas preguntas básicas que un VC podría plantear inicialmente para determinar si el proceso de generación de datos de una startup realmente puede crear resultados utilizables para la IA:
- ¿Está automatizada la captura de datos para permitir la ampliación?
- ¿Los datos se almacenan en entornos de nube seguros con copias de seguridad automatizadas?
- ¿Cómo se gestiona y garantiza el acceso a la infraestructura y a los recursos informáticos relevantes?
- ¿Están los procesos de procesamiento de datos completamente automatizados, con rigurosos controles de calidad de los datos implementados para limitar la contaminación proveniente de puntos de datos contaminados?
- ¿Se puede acceder fácilmente a los datos en toda la empresa para potenciar la creación de modelos de aprendizaje automático y las decisiones basadas en datos?
- ¿Cómo se implementa la gobernanza de datos?
- ¿Existe una estrategia de gestión de datos?
- ¿Se realiza un seguimiento y se puede acceder a las versiones de datos y modelos de ML, garantizando que los modelos de ML siempre funcionen con la última versión de datos?
Recibir respuestas sólidas a estas preguntas puede ayudar a determinar el conocimiento que tiene una empresa de los principios subyacentes de sus canales de datos. Esta comprensión, a su vez, ayudará a medir la calidad del resultado del modelo.
Marco 2: Las cinco V de la calidad de los datos
Una vez que se considera que la base tecnológica de una empresa es adecuada para la IA, también es necesario considerar cuidadosamente la calidad de los datos resultantes que se utilizan para entrenar sus modelos. Un marco común utilizado para capturar la clasificación de la calidad de los datos son las cinco V de la calidad de los datos. Representan cinco dimensiones clave de la calidad de los datos que los capitalistas de riesgo deben considerar al evaluar las nuevas empresas de IA:
- Veracidad: Los datos deben ser exactos y veraces.
- Variedad: Los datos deben ser diversos y representativos del mundo real.
- Volumen: los datos deben ser lo suficientemente grandes para entrenar el modelo de IA de manera efectiva.
- Velocidad: Los datos deben actualizarse con frecuencia para reflejar los cambios en el mundo.
- Valor: los datos deben ser útiles para que el modelo de IA pueda aprender de ellos.
Aquí hay algunas preguntas introductorias para ayudar a evaluar los datos de una empresa para las cinco V:
- ¿Tiene la startup una buena hipótesis sobre qué datos necesita crear para construir una capacidad diferenciada o un modelo útil?
- ¿Qué datos recogen?
- ¿También recopilan metadatos relevantes?
- ¿Cómo garantizan la exactitud y coherencia de los datos que recopilan?
- ¿Cómo planea la startup lidiar con el sesgo de datos?
- ¿Recopilan varios ejemplos para la misma pregunta o experimento?
- ¿Qué tan útiles son estos datos para el producto que están creando?
- ¿Cuál es la razón detrás de la recopilación de estos datos?
- ¿Tienen evidencia de que sus predicciones mejoran al recopilar y utilizar estos datos? En caso afirmativo, ¿cómo se correlaciona la cantidad de datos con la mejora de la predicción?
- ¿Qué tan fácil es para un competidor recopilar los mismos datos?
- ¿Cuánto tiempo les tomaría y cuánto les costaría hacerlo?
- Específicamente para una biotecnología, ¿qué tan bien se correlaciona el indicador que predicen con un criterio de valoración clínicamente relevante? ¿Hay evidencia de esto?
- ¿Cuál es el plan de la startup para garantizar la calidad de sus datos a lo largo del tiempo?
- ¿Cómo planea la startup proteger sus datos del acceso no autorizado?
- ¿Cómo planea la startup cumplir con las regulaciones de privacidad de datos?
Al considerar cuidadosamente las cinco V de la calidad de los datos, los capitalistas de riesgo pueden asegurarse de que están invirtiendo en nuevas empresas de IA que tienen los datos que necesitan para tener éxito. Si la startup puede responder las preguntas anteriores de manera convincente y sus datos obtienen una puntuación alta en las cinco dimensiones, es una buena señal de que se toman en serio la calidad de los datos y están adecuadamente equipados para aplicar sus modelos de IA.
Finalmente, los capitalistas de riesgo deben evaluar el compromiso de la startup con la seguridad de los datos. Esto incluye cosas como sus políticas de gobierno de datos, sus procedimientos de garantía de calidad de datos y sus planes de respuesta a violaciones de datos.
Interrogar al mercado para encontrar a los ganadores
En medio del rotundo rumor que rodea a la IA en los últimamente, el atractivo de inversiones sustanciales ha atraído a fundadores de startups dispuestos a exagerar su infraestructura e inflar capacidades en la búsqueda de capital.
Los capitalistas de riesgo exitosos están haciendo las preguntas correctas para interrogar a estas empresas a fondo y filtrando a los ganadores potenciales construidos sobre una base sólida de aquellos con una cáscara hueca que en última instancia están destinados al fracaso.
