
Inteligencia Artificial
Para Jae Lee, un científico de datos de formación, nunca tuvo sentido que el vídeo – que se ha convertido en una parte enorme de nuestras vidas, con el auge de plataformas como TikTok, Vimeo y YouTube -, fuera difícil de buscar debido a las barreras técnicas que plantea la comprensión del contexto. Buscar los títulos, las descripciones y las etiquetas de los vídeos siempre fue bastante fácil y no requería más que un algoritmo básico, pero buscar dentro de los vídeos momentos y escenas específicas estaba mucho más allá de las capacidades de la tecnología, particularmente si esos momentos y escenas no estaban etiquetados de manera obvia.
Para resolver este problema, Lee, junto con amigos de la industria tecnológica, creó un servicio en la nube para la búsqueda y comprensión de vídeos. Se convirtió Twelve Labs, que luego recaudó $ 17 millones en capital de riesgo. Radical Ventures lideró la extensión con la participación de Index Ventures, WndrCo, Spring Ventures, el CEO de Weights & Biases, Lukas Biewald, y otros, dijo Lee a TechCrunch en un correo electrónico.
“La visión de Twelve Labs es ayudar a los desarrolladores a crear programas que puedan ver, escuchar y comprender el mundo como lo hacemos nosotros, brindándoles la infraestructura de comprensión de video más poderosa”, dijo Lee.
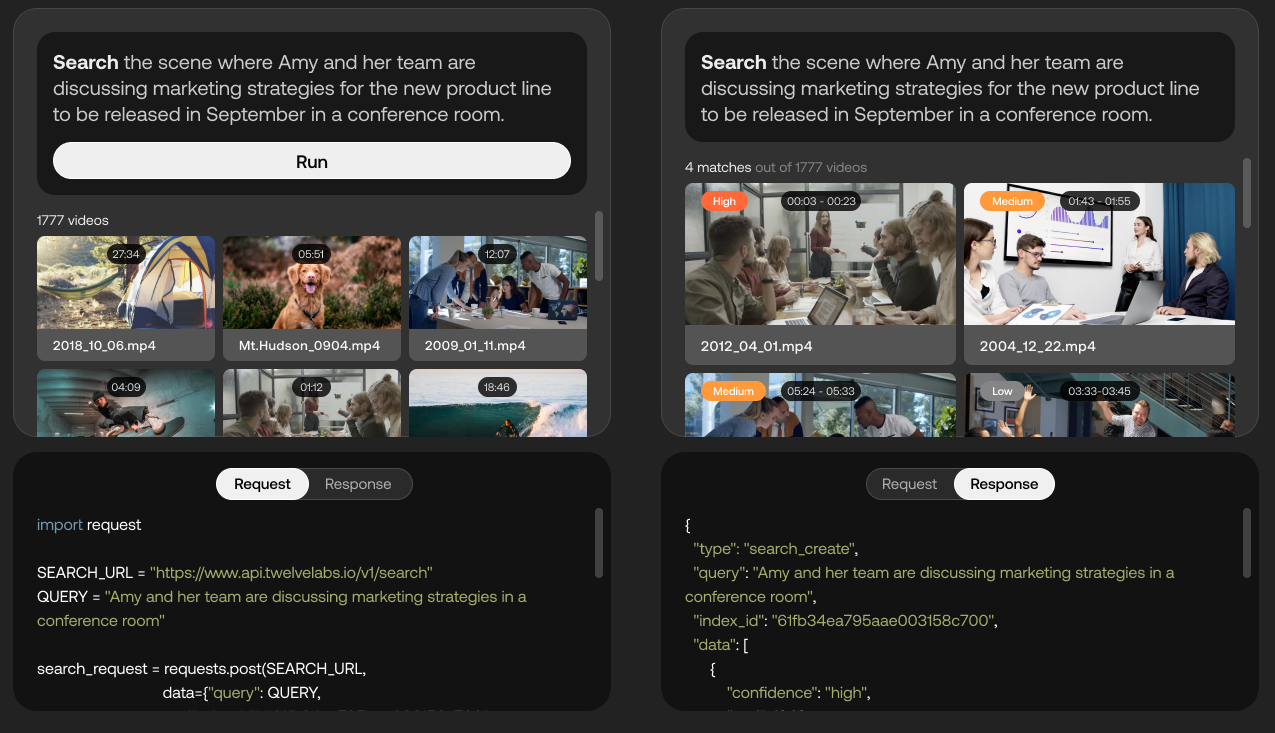
Una demostración de las capacidades de la plataforma Twelve Labs. Créditos de imagen: Twelve Labs
Twelve Labs, que actualmente se encuentra en versión beta cerrada, usa IA para intentar extraer «información rica» de videos como movimiento y acciones, objetos y personas, sonido, texto en pantalla y voz para identificar las relaciones entre ellos. La plataforma convierte estos diversos elementos en representaciones matemáticas llamadas «vectores» y forma «conexiones temporales» entre cuadros, lo que permite aplicaciones como la búsqueda de escenas de video.
“Como parte de lograr la visión de la compañía de ayudar a los desarrolladores a crear aplicaciones de video inteligentes, el equipo de Twelve Labs está construyendo ‘modelos básicos’ para la comprensión de video multimodal”, dijo Lee. «Los desarrolladores podrán acceder a estos modelos a través de un conjunto de API, realizando no solo búsquedas semánticas, sino también otras tareas como la ‘captización’ de videos de formato largo, la generación de resúmenes y preguntas y respuestas de videos».
Google adopta un enfoque similar para la comprensión de videos con su sistema MUM AI, que la empresa usa para potenciar las recomendaciones de videos en la Búsqueda de Google y YouTube seleccionando temas en los videos (por ejemplo, «materiales de pintura acrílica») según el audio, el texto y la imagen. Pero si bien la tecnología puede ser comparable, Twelve Labs es uno de los primeros proveedores en comercializarla; Google ha optado por mantener MUM interno y se niega a ponerlo a disposición a través de una API pública.
Dicho esto, Google, así como Microsoft y Amazon, ofrecen servicios (es decir, Google Cloud Video AI, Azure Video Indexer y AWS Rekognition) que reconocen objetos, lugares y acciones en videos y extraen metadatos enriquecidos a nivel de cuadro. También está Reminiz, una startup francesa de visión por computadora que afirma poder indexar cualquier tipo de video y agregar etiquetas tanto al contenido grabado como al transmitido en vivo. Pero Lee afirma que Twelve Labs se diferencia lo suficiente, en parte porque su plataforma permite a los clientes ajustar la IA a categorías específicas de contenido de video.
“Lo que hemos encontrado es que los productos de IA creados para detectar problemas específicos muestran una alta precisión en sus escenarios ideales en un entorno controlado, pero no se adaptan tan bien a los datos desordenados del mundo real”, dijo Lee. “Actúan más como un sistema basado en reglas y, por lo tanto, carecen de la capacidad de generalizar cuando ocurren variaciones. También vemos esto como una limitación arraigada en la falta de comprensión del contexto. La comprensión del contexto es lo que les da a los humanos la capacidad única de hacer generalizaciones en situaciones aparentemente diferentes en el mundo real, y aquí es donde Twelve Labs se destaca”.
Más allá de la búsqueda, Lee dice que la tecnología de Twelve Labs puede impulsar cosas como la inserción de anuncios y la moderación de contenido, determinando de manera inteligente, por ejemplo, qué videos que muestran cuchillos son violentos versus instructivos. También se puede usar para análisis de medios y comentarios en tiempo real, dice, y para generar automáticamente carretes destacados a partir de videos.
Un poco más de un año después de su fundación (marzo de 2021), Twelve Labs tiene clientes que pagan y un contrato de varios años con Oracle para entrenar modelos de IA utilizando la infraestructura en la nube de Oracle. De cara al futuro, la startup planea invertir en desarrollar su tecnología y expandir su equipo.
“Para la mayoría de las empresas, a pesar del enorme valor que se puede lograr a través de modelos grandes, realmente no tiene sentido que entrenen, operen y mantengan estos modelos ellos mismos. Al aprovechar una plataforma de Twelve Labs, cualquier organización puede aprovechar las poderosas capacidades de comprensión de video con solo unas pocas llamadas intuitivas a la API”, dijo Lee. “La dirección futura de la innovación en IA se dirige directamente hacia la comprensión de video multimodal, y Twelve Labs está bien posicionado para ampliar aún más los límites en 2023”.
