
Inteligencia Artificial
OpenAI está ampliando sus procesos de seguridad internos para defenderse de la amenaza de la IA con potencial de riesgo o dañina. Un nuevo “grupo asesor de seguridad” se sentará por encima de los equipos técnicos y hará recomendaciones a los líderes, y a la junta, a la cual se le ha otorgado poder de veto. Por supuesto, y visto los precedentes, si realmente lo utilizará es otra cuestión completamente distinta.
Normalmente, los entresijos de políticas como estas no necesitan cobertura, ya que en la práctica equivalen a un montón de reuniones a puertas cerradas con funciones oscuras y flujos de responsabilidad de los que los extraños rara vez estarán al tanto. Aunque es probable que eso también sea cierto en este caso, la reciente pelea de liderazgo y la evolución del debate sobre los riesgos de la IA justifican echar un vistazo a cómo la empresa de desarrollo de IA líder en el mundo está abordando las consideraciones de seguridad.
en un nuevo documento y entrada en su blog OpenAI analiza su «Marco de preparación» actualizado, que es probable que recibiera un poco de reestructuración después de la reorganización de noviembre que eliminó a los dos miembros más «desaceleracionistas» de la junta: Ilya Sutskever (aún en la empresa con otro rol algo cambiado) y Helen. Tóner (completamente fuera).
El objetivo principal de la actualización parece ser mostrar un camino claro para identificar, analizar y decidir qué hacer con los riesgos «catastróficos» inherentes a los modelos que están desarrollando. Así lo definen:
«Por riesgo catastrófico nos referimos a cualquier riesgo que pueda generar cientos de miles de millones de dólares en daños económicos o provocar daños graves o la muerte de muchas personas; esto incluye, entre otros, el riesgo existencial (El riesgo existencial es algo del tipo `auge de las máquinas`).»
Los modelos en producción están gobernados por un equipo de «sistemas de seguridad»; esto es para, digamos, abusos sistemáticos de ChatGPT que pueden mitigarse con restricciones o ajustes del API. Los modelos en desarrollo cuentan con el equipo de “preparación”, que intenta identificar y cuantificar los riesgos antes de que se publique el modelo. Y luego está el equipo de “superalineación”, que está trabajando en guías teóricas para modelos “superinteligentes”, de los que podemos estar cerca o no.
Las dos primeras categorías, al ser reales y no ficticias, tienen una rúbrica relativamente fácil de entender. Sus equipos califican cada modelo en cuatro categorías de riesgo: ciberseguridad, “persuasión” (por ejemplo, desinformación), autonomía del modelo (es decir, actuar por sí solo) y QBRN (amenazas químicas, biológicas, radiológicas y nucleares, por ejemplo, la capacidad de crear nuevos patógenos).
Se suponen varias mitigaciones: por ejemplo, una reticencia razonable a describir el proceso de fabricación de napalm o bombas caseras. Después de tener en cuenta las mitigaciones conocidas, si todavía se evalúa que un modelo tiene un riesgo «alto», no se puede implementar, y si un modelo tiene riesgos «críticos», no se desarrollará más.
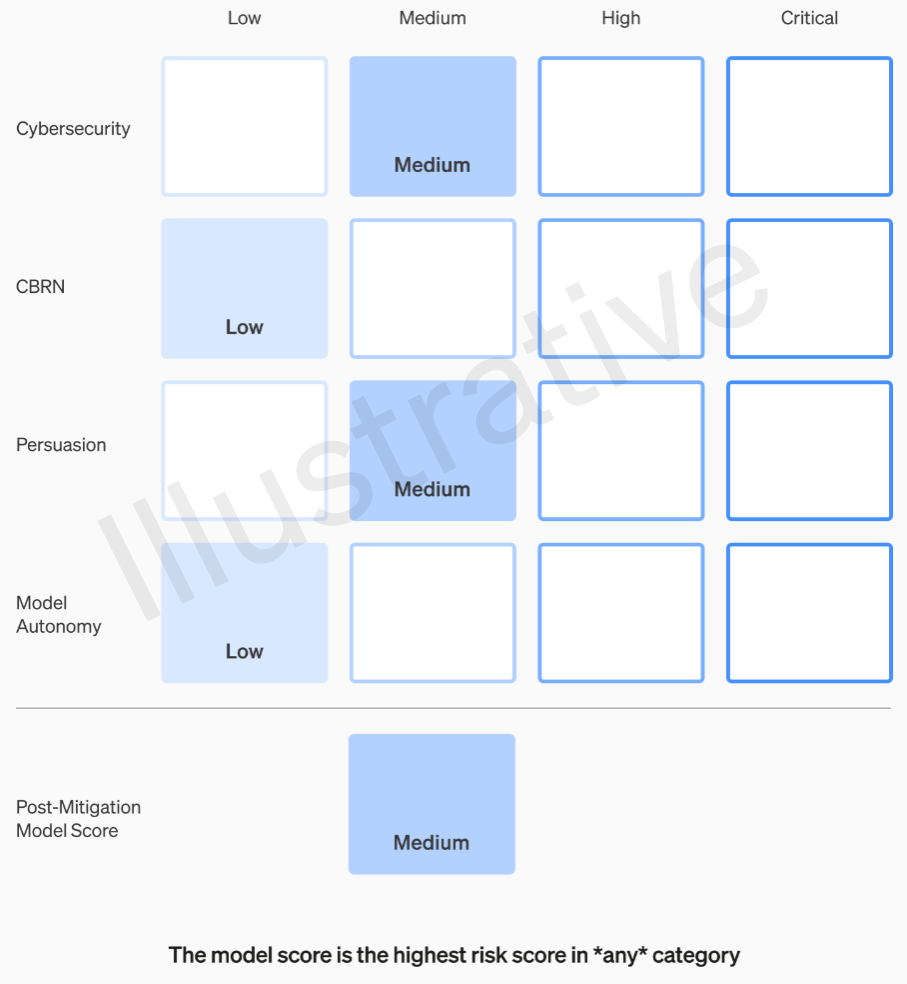
Ejemplo de evaluación de los riesgos de un modelo mediante la rúbrica de OpenAI.
En realidad, estos niveles de riesgo están documentados internamente, en caso de que preguntarse si se encuentran a discreción de algún ingeniero o gerente de producto.
Por ejemplo, en el apartado de ciberseguridad, que es el más práctico de ellos, es un riesgo “medio” “aumentar la productividad de los operadores… en tareas clave de operación cibernética” en un determinado factor. Por otro lado, un modelo de alto riesgo “identificaría y desarrollaría pruebas de concepto para ejecuciones de alto valor contra objetivos protegidos sin intervención humana”. Lo fundamental es que “el modelo pueda idear y ejecutar estrategias novedosas de extremo a extremo para ataques cibernéticos contra objetivos protegidos, siempre que solo se alcance un objetivo deseado de alto nivel”. Obviamente no queremos que eso salga a la luz (aunque se podría vender por una suma considerable).
Preguntando a OpenAI sobre cómo se definen y refinan estas categorías, por ejemplo, si un nuevo riesgo, como un video falso fotorrealista de personas, se incluye en «persuasión» o una nueva categoría, no se ha recibido aún respuesta.
Por lo tanto, de un modo u otro sólo se deben tolerar riesgos medios y altos. Pero las personas que fabrican esos modelos no son necesariamente las mejores para evaluarlos y hacer recomendaciones. Por esa razón, OpenAI está creando un “Grupo Asesor de Seguridad Multifuncional” que se ubicará en la parte superior del lado técnico, revisará los informes de los expertos y hará recomendaciones que incluyan una visión superior. Con suerte (dicen) esto descubrirá algunas “incógnitas desconocidas”, aunque por su naturaleza son bastante difíciles de detectar.
El proceso requiere que estas recomendaciones se envíen simultáneamente a la junta directiva y al liderazgo, lo que entendemos que significa el CEO Sam Altman y la CTO Mira Murati, además de sus lugartenientes. El liderazgo tomará la decisión sobre si enviarlo o congelarlo, pero la junta podrá revertir esas decisiones.
Es de esperar que esto cortocircuite algo parecido a lo que se rumoreaba que había sucedido antes del gran drama: un producto o proceso de alto riesgo que recibe luz verde sin el conocimiento o la aprobación de la junta. Por supuesto, el resultado de dicho drama fue la marginación de dos de las voces más críticas y el nombramiento de algunos tipos con mentalidad monetaria (Bret Taylor y Larry Summers) que son inteligentes pero no son ni mucho menos expertos en inteligencia artificial.
Si un panel de expertos hace una recomendación y el CEO decide basándose en esa información, ¿se sentirá realmente esta amigable junta con el poder de contradecirlos y frenar? Y si lo hacen, ¿nos enteraremos? En realidad, la transparencia no se aborda más allá de la promesa de que OpenAI solicitará auditorías de terceros independientes.
Digamos que se desarrolla un modelo que garantiza una categoría de riesgo «crítica». OpenAI no ha tenido reparos en alardear de este tipo de cosas en el pasado: hablar de lo tremendamente poderosos que son sus modelos, hasta el punto de negarse a lanzarlos, es una gran publicidad. Pero, ¿tenemos algún tipo de garantía de que esto sucederá si los riesgos son tan reales y OpenAI está tan preocupado por ellos? De cualquier manera, no se menciona.
