
Usuarios del Club TRPlane
La empresa Meta ha anunciado la suspensión de sus planes para iniciar el entrenamiento de sus sistemas de inteligencia artificial con datos de usuarios en la Unión Europea y el Reino Unido.
La medida se produce después de que la Comisión Irlandesa de Protección de Datos (DPC), el principal regulador de Meta en la Unión Europea, rechazara la propuesta, actuando en representación de diversas autoridades de protección de datos en el bloque. Asimismo, la Oficina del Comisionado de Información (ICO) del Reino Unido ha solicitado a Meta que suspenda sus planes hasta que pueda abordar las inquietudes planteadas.
La Comisión de Protección de Datos (DPC) expresó su satisfacción por la determinación de la empresa Meta de suspender sus proyectos para el entrenamiento de su modelo de lenguaje extenso con el uso de contenido público compartido por adultos en Facebook e Instagram en todos los países de la Unión Europea y del Espacio Económico Europeo (UE/EEE), según indicó la DPC en un comunicado. La mencionada resolución fue el resultado de un intenso diálogo entre la DPC y Meta. La DPC continuará colaborando con Meta en este asunto, en conjunto con las autoridades de protección de datos de la Unión Europea.
A pesar de que Meta ya está utilizando el contenido generado por los usuarios para el entrenamiento de su inteligencia artificial en mercados como el de los Estados Unidos, las rigurosas regulaciones del Reglamento General de Protección de Datos (GDPR) en Europa han planteado desafíos para Meta (y otras compañías) que buscan perfeccionar sus sistemas de inteligencia artificial, incluyendo grandes modelos de lenguaje con datos de entrenamiento generados por los usuarios.
No obstante, Meta inició la comunicación a los usuarios acerca de una próxima modificación en su política de privacidad. Esta modificación le otorgará el derecho de utilizar contenido público de Facebook e Instagram para el entrenamiento de su inteligencia artificial, incluyendo comentarios, interacciones con empresas, actualizaciones de estado, fotografías y sus respectivas leyendas. La empresa justificó esta medida con la necesidad de reflejar «la diversidad de idiomas, geografía y referencias culturales de los individuos en Europa«.
La entrada en vigor de los cambios estaba programada para el 26 de junio de 2024, en un plazo de 12 días. Sin embargo, la organización activista de la privacidad sin fines de lucro NOYB («None of your business, No es asunto tuyo») ha presentado 11 quejas ante los países miembros de la Unión Europea, alegando que Meta está infringiendo varios aspectos del Reglamento General de Protección de Datos (RGPD). Una de estas quejas se refiere al tema de la obtención de consentimiento frente a la opción de exclusión voluntaria. Se argumenta que al procesar datos personales, se debe solicitar permiso a los usuarios en lugar de requerir que tomen medidas para negarse.
Por su parte, Meta fundamentaba sus acciones en una disposición del Reglamento General de Protección de Datos (RGPD) conocida como «intereses legítimos» para argumentar su cumplimiento con las normativas. Meta ha recurrido en más de una ocasión a esta base legal para su defensa, como lo hizo previamente al justificar el tratamiento de publicidad dirigida a usuarios europeos.
La suspensión de la implementación de los cambios propuestos por Meta por parte de los reguladores siempre fue una posibilidad plausible, especialmente debido a la complejidad con la que la empresa había diseñado el proceso de exclusión de la utilización de datos por parte de los usuarios. A pesar de que la compañía afirmó haber enviado más de 2 mil millones de notificaciones para informar a los usuarios sobre las próximas modificaciones, estas notificaciones no se destacaron de manera prominente en los feeds de los usuarios, como sucede con otros mensajes de interés público relevante, como las indicaciones para participar en elecciones. Por lo tanto, al aparecer junto a las notificaciones estándar, como felicitaciones por cumpleaños de amigos, alertas de etiquetado en fotos, anuncios de grupos, entre otros, era fácil que los usuarios pasaran por alto esta información si no revisaban regularmente sus notificaciones.
Los usuarios que visualizaron la notificación no tendrían conocimiento inmediato de la posibilidad de objetar o cancelar su suscripción, ya que la invitación simplemente instaba a hacer clic para conocer el uso que Meta hará de su información. No se incluyó ninguna indicación sobre la existencia de una opción en este caso.
Imagen: Meta
Los usuarios no tenían la opción de abstenerse de utilizar sus datos, sino que debían completar un formulario de objeción en el que exponían sus razones para no autorizar el procesamiento de sus datos. La decisión de cumplir con esta solicitud quedaba a discreción de Meta, aunque la compañía afirmaba que atendería cada solicitud.
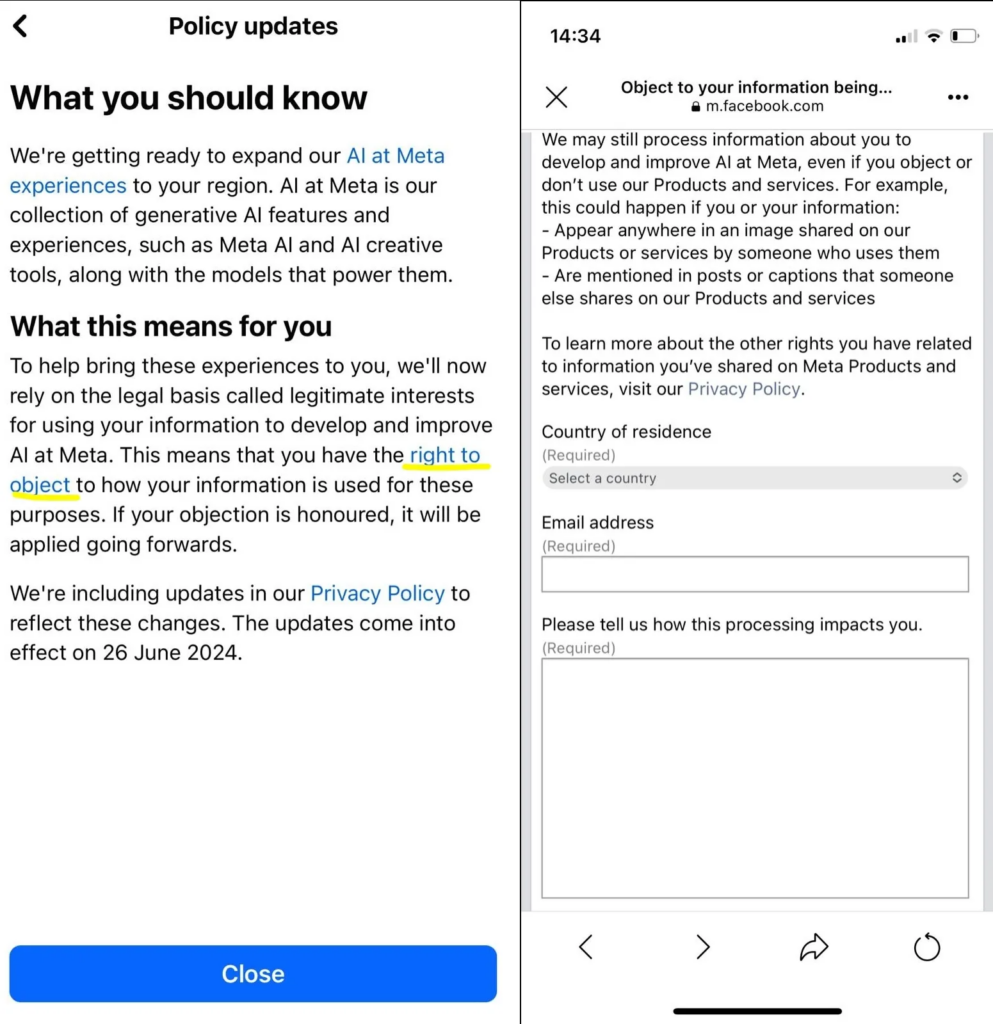
Formulario de objeción de Facebook. Imagen: Meta
A pesar de que el formulario de objeción estaba disponible desde la notificación inicial, aquellos que buscaban activamente el formulario en la configuración de su cuenta encontraban dificultades.
En el sitio web de Facebook, el procedimiento para acceder a la sección de configuración de privacidad y luego a la información sobre el uso de la inteligencia artificial generativa por parte de Meta implicaba seguir una serie de pasos. Primero, se debía hacer clic en la Foto de perfil ubicada en la esquina superior derecha de la pantalla. Posteriormente, se accedía a la sección de configuración y privacidad, donde se seleccionaba el centro de privacidad. Dentro de esta sección, se buscaba la información sobre la inteligencia artificial generativa en la sección dedicada a Meta. Más adelante, se descendía por la página hasta llegar a la sección de «más recursos», donde se encontraba el enlace titulado «Cómo Meta utiliza la información para los modelos de IA generativa«. Para acceder al formulario de «derecho a objetar» de la empresa, era necesario leer aproximadamente 1.100 palabras antes de encontrar un enlace discreto. Este mismo proceso se repetía en la aplicación móvil de Facebook.

El enlace al formulario para ejercer el derecho de oposición. Imagen: Meta
El gerente de comunicaciones de políticas de Meta, Matt Pollard, explicó que el proceso requiere que el usuario presente una objeción en lugar de aceptarlo, basándose en la publicación de blog de la empresa. En dicha publicación se argumenta que la base jurídica de «intereses legítimos» es la más adecuada para procesar datos públicos a gran escala con el fin de entrenar modelos de inteligencia artificial, al mismo tiempo que se respetan los derechos de las personas.
Para lograr una mayor participación de los usuarios dispuestos a proporcionar sus datos, se consideró que suscribirse a esta notificación no generaría la suficiente «escala». Por lo tanto, se optó por emitir una notificación individual entre otras notificaciones de los usuarios, ocultando el formulario de objeción detrás de varios clics para aquellos que buscan la «exclusión voluntaria» de manera independiente. Posteriormente, se les requería justificar su objeción en lugar de ofrecerles una opción directa de exclusión.
En una publicación reciente de blog, Stefano Fratta, quien se desempeña como director de compromiso global para la política de privacidad en Meta, expresó su decepción ante la solicitud recibida por parte del DPC en el día de hoy.
Fratta escribió que la decisión representa un retroceso en el avance de la innovación europea, la competencia en el desarrollo de la Inteligencia Artificial y ocasionará demoras en la implementación de los beneficios de la IA en la población en Europa. Expresó confianza en que su enfoque se ajusta a las leyes y regulaciones de la CEE y UK, destacando que la capacitación en IA no es exclusiva de sus servicios y que mantienen un nivel de transparencia superior al de otros actores de la industria.
La competencia en el desarrollo de inteligencia artificial
Todo esto no es una novedad, Meta participa en una competencia de desarrollo de inteligencia artificial que ha resaltado la extensa cantidad de datos que las grandes empresas tecnológicas poseen sobre la población.
A principios de este año, se dio a conocer que Reddit ha firmado un contrato que le permitirá obtener más de 200 millones de dólares en los próximos años al otorgar licencias de sus datos a empresas como OpenAI, creador de ChatGPT, y Google. Por otro lado, Google, una de estas empresas, se encuentra actualmente enfrentando cuantiosas multas debido a su uso de contenido protegido por derechos de autor para el entrenamiento de sus modelos generativos de inteligencia artificial.
Los esfuerzos realizados también evidencian la extensión a la que las empresas están dispuestas a llegar para garantizar la utilización de estos datos dentro de los límites legales existentes. La opción de participar rara vez se considera, y el proceso para optar por no participar suele ser excesivamente complicado. Recientemente, se identificó una redacción ambigua en una política de privacidad de Slack que insinuaba la posibilidad de utilizar los datos de los usuarios para el entrenamiento de sus sistemas de inteligencia artificial, y que los usuarios solo podrían rechazar participar enviando un correo electrónico a la empresa.
El año pasado, Google proporcionó a los editores online una opción para evitar que sus sitios web fueran utilizados en el entrenamiento de sus modelos, a través de la inserción de un fragmento de código en sus sitios. Por otro lado, OpenAI está desarrollando una herramienta especializada que permitirá a los creadores de contenido excluir el entrenamiento de su inteligencia generativa de IA, con una fecha estimada de lanzamiento para el año 2025.
Aunque los esfuerzos de Meta para entrenar su inteligencia artificial con el contenido público de los usuarios en Europa se encuentran actualmente suspendidos, es probable que se retomen de una manera diferente después de consultar con el Comisionado de Protección de Datos y el Comisionado de Información, con la esperanza de implementar un nuevo proceso de obtención de permiso por parte de los usuarios.
En una declaración reciente, Stephen Almond, director ejecutivo de riesgo regulatorio de la ICO, enfatizó la importancia de que el público confíe en la protección de sus derechos de privacidad al utilizar la inteligencia artificial generativa. Almond señaló la necesidad de monitorear a los principales desarrolladores de esta tecnología, como Meta, para revisar las medidas de seguridad implementadas y asegurar la protección de los derechos de información de los usuarios en el Reino Unido.
